This was the first set lab of lab studies [1] we conducted on very early prototypes of
Mavo HTML (nee Wysie), Formula² (nee WysieScript), and Madata (which did not yet have a separate name or implementation).
Data Update Actions were not yet supported.
The primary focus of this first set of studies was to evaluate the usability of Mavo HTML,
Formula² as it relates to Mavo, and to a much lesser extent Madata as it relates to Mavo.
To better understand the results, it is essential to discuss the design of Mavo at the time of the study.
since its constituent languages and components have evolved significantly since then (partly thanks to the findings from these studies!).
Initially, all Mavo attributes (that were not part of any existing standard) used the prefix data- rather than mv-.
For example, mv-multiple was then data-multiple.
While HTML handles any attribute name well, to prevent future HTML features from breaking existing websites,
the HTML5 specification [2] defines that attributes beginning with data- are reserved for custom data attributes,
and any other unknown attribute should be considered invalid.
This leaves third-party languages, libraries, or frameworks that define multiple attributes
with having to choose between using invalid HTML,
using data- prefixes which makes it unclear which attributes belong to what third-party technology,
or use a verbose prefix like data-mv-.
The first version of Mavo HTML went with the second option,
favoring HTML validity over brevity or clarity.
Later versions switched to supporting both the former (mv-*) and the latter (data-mv-*),
and eventually the latter was dropped for simplicity (and due to lack of use).
At the time there was no mv-app attribute (or even a data-app one) — data-storage served double duty:
It both enabled Mavo functionality on an HTML subtree and specified the data location.
The original thinking was that since enabling Mavo functionality on a subtree without also asking Mavo to do something
does not produce any visible change,
which would violate the design principle that incremental user effort should result in incremental value.
Since an explicit opt-in does not produce any visible change, it was creating a highly likely error condition,
where authors use data-storage but forget to enable Mavo functionality on the subtree.
However, this was also a textbook case of undersirable concept overloading [3].
First, some awkward situations, such as when applications did not need to store data anywhere (e.g. a mortgage calculator),
yet still had to specify a data-storage attribute with no value to enable Mavo functionality.
Second, it seemed unclear why we privileged that particular attribute,
so we later added more attributes to the set of attributes that could enable Mavo functionality,
making it nontrivial to figure out which elements on a page were Mavo applications.
Furthermore, there was no way to provide a unique identifier for an application,
since there was no attribute that did not also serve another purpose.
Eventually, all of these issues led to the introduction of the mv-app attribute.
At the time, conditional logic and computation in general was only possible with expressions.
The mv-if and mv-value attributes were added to Mavo as a result of this study.
In our evaluation, we examined whether Mavo could be learned and applied by novice web authors to build a variety of
applications in a short amount of time.
In order to understand both the usability and flexibility of Mavo, we designed two user studies.
For a first Structured study, we authored static web page mockups of two representative CRUD applications and then gave users a series of Mavo authoring tasks that gradually evolved those mockups into complete applications.
This study focused on learnability and usability.
For a second Freestyle study, before telling users about Mavo (so that they would not feel constrained by its capabilities),
we asked them to create their own mockup of an address book application.
Then, during the study, we asked them to use Mavo to convert their mockups into functional applications.
This study focused on whether Mavo’s capabilities were sufficient to create applications as envisioned by users.
We carried out the two user studies using three applications.
The applications were designed with hierarchical data to test users’
ability to generate hierarchical data schemas and perform computations on them.
To facilitate replication of our study, we have published all our study materials online1mavo.io/uist2016/study.
We recruited 20 participants (mean age 35.9, SD 10.2; 35% male, 60% female, 5% other)
by publishing a call to participation on social media and local web design meetup groups.
Of these, 13 performed only the Structured study,
3 performed only the Freestyle study, and 4 performed both.
Participant familiarity with web development languages.
All of our participants marked their HTML skills as intermediate (rich text formatting, basic form elements, tables) or above.
However, most (19/20) described themselves as intermediate or below in JavaScript (Table 7.1).
When they were asked about programming languages in general, 13/20 described themselves as
beginners or worse in any programming language, while 7/20 considered themselves intermediate or
better.
User study participants’ familiarity with data specification languages.
In addition, when we asked participants about their
experience with various data concepts, only 4/20 stated they could
write JSON, 5/20 could write SQL, and none could write any type of HTML metadata (RDFa, Microdata, Microformats).
We began by asking participants a series of open-ended questions about their experience with web development and web publishing.
We asked them what kind of applications and functionality they wished they could create but could not due to lack of time or ability.
Before either study, we gave each user a tutorial on Mavo, interspersed with
practice tasks on a simple inventory application.
This took 45 minutes on average and covered the property attribute (10 minutes),
the data-multiple attribute (10 minutes),
and expressions using the
[] syntax, broken down into
how to reference properties and perform computations (5 minutes),
aggregates such as count() (10 minutes),
and iff() syntax and logic (10 minutes).
For the Structured study, we created two applications:
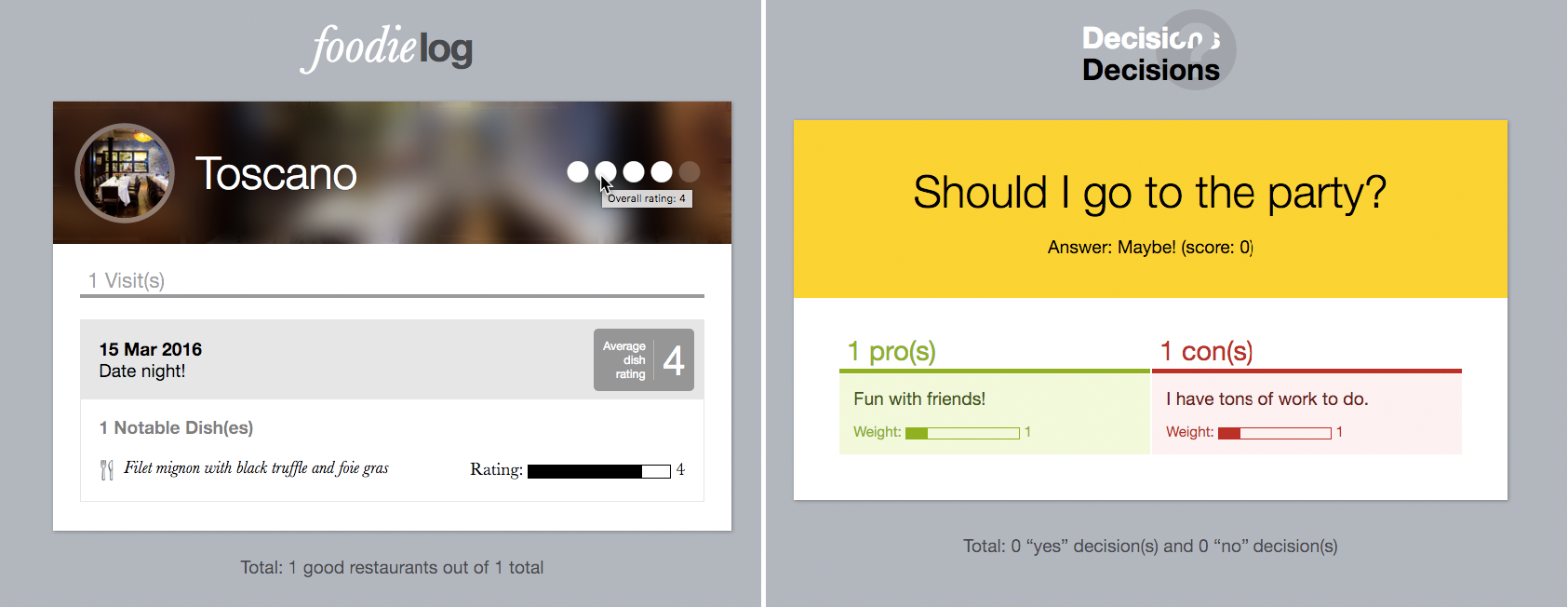
Decisions app: A tool for making decisions by summing weighted pros and cons.
The application also shows a suggested decision based on the sums of pro and con weights.
Foodie log: A restaurant visit tracker that includes dishes eaten on each visit with individual ratings per dish.
The application also computes average ratings for each visit and each restaurant.
Task category
Example task
Example code
Med. time
Success
Make editable
Foodie: 1, Decisions: 1
Make the restaurant information editable (name, picture, url, etc)
<h1 property="name"> Toscano</h1>
3:00
100%
Allow multiple
Foodie: 3, Decisions: 2
Make it possible to add more pros and cons.
<article property="pro" data‑multiple>
1:15
100%
Simple reference
Foodie: 3, Decisions: 3
Make the header background dynamic (same image as the restaurant picture)
<header style=" background: url([pic])">
0:43
88%
Simple aggregate
Foodie: 3, Decisions: 2
Make the visit rating dynamic (average of dish ratings)
[average(dishRating)]
0:55
97.5%
Multi-block aggregate
Foodie: 1, Decisions: 0
Make the restaurant rating dynamic (average of visit ratings)
<meter value="[average(visitRating)]">
2:00
77.8%
Filtered aggregate
Foodie: 1, Decisions: 1
Show a count of good restaurants
[count(rating > 3)] good restaurants
6:10
70.9%
Conditional
Foodie: 0, Decisions: 1
Show "Yes" if the score is positive, "No" if it's negative, "Maybe" if it’s 0.
User study tasks are shown in the mockups that were given to participants, and results are broken down by task category.
The green arrows point to element backgrounds, which participants made dynamic via inline styles or class names.
Page elements involved in specific tasks are outlined with color codes shown in the table.
“Make editable” tasks are not shown to prevent clutter.
17 subjects were given static HTML and CSS mockups of one of these applications and were asked to
carry out a series of tasks by editing the HTML.
These tasks tested their ability to use different aspects of Mavo, as shown in Figure 7.1.
Eight of these users were given a mockup of a Decisions app
and the other 9 were given a mockup of a Foodie log.
Each subject was shown a fully functional version of their respective application (but not its HTML source)
before being given the static HTML template.
While a CSS style file was provided, they did not have to look at it.
We provided tasks to the user one at a time, letting them complete one before revealing the next.
Tasks were administered in the same order, and we measured the time each subject took to complete the task as well as screen recorded their typing.
Participants were asked to speak aloud their thoughts and confusions as they worked.
Researchers were silent except to alert subjects to spelling mistakes and to explain HTML and CSS concepts—such as how to set a value on a <meter> tag — if
subjects were unaware of them.
If subjects spent over 15 minutes on a task but were not close to succeeding,
the researchers stepped in to offer hints or explain the answer, and marked the task as failed.
In the case of the Decisions app, users had 10 tasks to complete, while for the Foodie log, users had 12 tasks.
The tasks increased in difficulty in order to challenge the users.
We grouped the tasks into 7 categories, where each category tests a particular aspect of Mavo.
Example tasks, code solutions, and the number of tasks in each category per application is in Figure 7.1.
As footnoted earlier, all this task data is available online.
A description of each task type and what it entails follows:
Make editable Adding property attributes to different HTML tags to make them editable.
Allow multiple Turn an element into a collection, by adding property and data-multiple.
Simple reference Display the value of a property somewhere else, via a [propertyName] expression.
Simple aggregate Show the result of a simple aggregate calculation, such as the count or sum of something.
Multi-block aggregate Aggregate calculation on a dynamic property, such as an average of counts.
Filtered aggregate Show how many items satisfy a given condition.
Conditional Show different text depending on a condition.
Participant responses to the question “How long do you think it would take you to build this application?” before learning about Mavo.
In the Structured studies, before providing the tasks,
we showed users the finished application they were tasked to create and asked them how long they thought it would take them.
Of the 17 users, 5 estimated it would take them several hours, 6 estimated days, 3 estimated weeks, and 3 estimated months.
Some users said that they would need to learn new skills or that they had no idea where to start.
After going through the tutorial, 6 users went on to complete all the tasks for their application with no failures,
1 user had no failures but had to leave before the last task, and 10 users failed at one or more tasks.
The 6 users who completed all tasks successfully took on average 17.3 minutes (Decisions, 10 tasks) and 22.5 minutes (Foodie, 12 tasks) to build the entire application.
Of the 10 people who failed one or more times,
5 failed on 1 task, 2 failed on 2 tasks, and 3 failed on 3 tasks.
All failures were concentrated on expression tasks, usually the most difficult ones.
The success rate for basic CRUD functionality was 100%.
Figure 7.1 shows the median time taken and success rate for each category of task for all 17 users.
As can be seen, some task categories were easier for
participants to carry out than others.
For instance, all participants quickly learned where to place the
property and data-multiple attributes, taking a median of 3 minutes to make several elements editable via property and a little over a minute to turn single elements into collections.
Almost all participants were also able to display simple aggregates, such as showing a count of restaurant visits or a decision score (sum of pro weights - sum of con weights).
However, some participants struggled with more complicated expressions, such as conditionals or multi-block aggregates.
We explore some of the more common issues next.
We asked these 17 participants who built either the Decisions or Foodie app to rate the difficulty of converting the static page to the fully realized application.
They were asked to rate this twice: once after seeing a demo of the final application but before learning about Mavo, and once after going through all the tasks with Mavo.
On a 5-point Likert scale, the reported difficulty rating after building the app with Mavo dropped 2.06 points on average from its pre-Mavo rating.
The most prevalent error was putting data-multiple on the wrong element — usually the parent container — with 40% of participants stumbling on it at some point.
However, as soon as users saw that they were getting copies of the wrong element, they immediately figured out the issue.
As the user’s intent was always clear, a WYSIWYG editor would solve this in the future.
Another similarly common and quick-to-fix mistake was forgetting data-multiple (25%).
None of these mistakes led to task failures.
We noticed that users had a hard time grasping or realizing they could do concatenation.
Both the Decisions and Foodie applications included 3 simple reference tasks.
We noticed that the failure rate was significantly higher (20-25% vs 0%)
when the variable part was not separated by whitespace from the static part of the text,
as shown in Table 7.3.
Perhaps the whitespace allowed users to see the variable part as a separate entity,
and avoid building a mental model that involves concatenation.
Another common mistake was using sum() instead of count() (20% of participants).
This may be because they are thinking of counting in terms of “summing how many items there are”,
Another theory might suggest that they are more familiar with sum(), due it being far more common than count() in spreadsheets.
However, this is unlikely as there was no correlation between spreadsheet familiarity and occurrence of this mistake.
We noticed that some participants frequently copied and pasted expressions when they needed the same calculation in different places.
A DRY (Don’t Repeat Yourself) strategy familiar to
programmers would be to create an
intermediate variable by surrounding the
expression in one place with a tag (such as <span> or <meta>) that also has a
property, so that it can be referenced elsewhere.
These intermediate properties would reduce clutter
and consequently reduce future mistakes down the road; they would also make it easier to modify computations globally.
This idea
might however be counterintuitive in Mavo as it calls for creating a tag in the
HTML that is never intended to be part of the presentation,
conflicting with the idea that one authors the application by authoring
what they want to see.
The Structured tasks with the lowest success rate (70.9%) were those that
required counting with a filter (count(rating > 3)).
25% of
participants tried solving these with conditionals, usually of the
form iff(rating > 3, count(rating)), which just printed out the number of ratings, since the condition is true if there is at least one rating larger than 3.
Most who succeeded remembered or (more often) guessed that they could put a conditional inside count and seemed almost surprised when it worked.
Another way of completing this task would be to declare
intermediate hidden variables computing e.g. rating > 3 inside each
restaurant or decision and then sum or count them outside that scope.
Only 10% of participants tried this method, again
suggesting that intermediate variables are a foreign concept to this
population.
Most participants found iff() to be one of the hardest
concepts to grasp.
40% of subjects tried iff() when it
was not needed, for instance in simple reference tasks.
25% of users were unable to successfully complete
the conditional task, which required two nested iff()s or three adjacent iff() statements, each controlling the appearance of one of the designated words (“Yes”, “Maybe”, or “No”).
The latter strategy was only attempted by 37.5% of participants.
In post-study discussions, some users mentioned how conditionals reminded them of what they found hard about programming:
“That’s some math and logic which are not my strong points.
Just seeing those if statements…I did a little bit of Java and I remember those always screwed me over in that class.
No surprise that that also tripped me up here.”
Another user reflected on how having multiple ways of doing something made it more difficult:
“It’s hard because there are often multiple ways of doing something.
And knowing which one would be the most efficient and best way to do it without making a mistake in the process was hard for me."
Our second Freestyle user study involved a third Own Address Book application.
During recruitment, subjects were asked to create their own static mock-up of an address book on their own time prior to meeting us, without being told why.
The 7 subjects who complied were assigned to the Freestyle study (3 also did the Structured study first).
During our meeting (and after the tutorial), they were asked to
add Mavo markup to their own mockup to turn it into a working application.
We added this second study to address several questions.
First, we wanted to be sure that our own HTML was not “optimized” for Mavo.
Because users were not aware of Mavo at the time they created their
application, their decisions were not influenced by
perceived strengths and limitations of the Mavo approach.
We can
therefore posit that these mockups reflected their preferred concept
of a contact manager application.
Thus, this study served to
test whether Mavo is suitable for animating applications
that users actually wanted to create.
At the same time, it tested
whether users could effectively use Mavo to animate “normal” HTML
that was written without Mavo in mind.
Before this Freestyle study, we provided no specification of how the
application should work or look, except to say that users only needed
to use HTML and CSS; that if there were lists, they only needed to
provide one example in the list; and that the mockup needed to contain at least
a name, a picture, and a phone number.
Then, during the study session, we asked them
to use Mavo to make their mockup fully
functional in any way they chose.
If the application they
envisioned was very simple, after they successfully implemented their
application, we encouraged them to consider more complex features, as described in the a section below.
Since what the user worked on depended on their own envisioned implementation, we did not have explicitly defined tasks throughout.
However, we did encourage users to try more advanced Mavo capabilities by suggesting the following tasks if they ran out of ideas:
Allow phone numbers (or emails) to have a label, such as “Home” or “Work” [Make editable]
Allow multiple phone numbers (and/or emails, postal addresses) [Allow multiple]
Provide a picture alt text that depends on the person’s name (for example, “John Doe’s picture”) [Simple reference]
Show a total count of people (and/or phone numbers, emails) [Simple aggregate]
Show “person” vs “people” in the heading, depending on how many contacts there are. [Conditional]
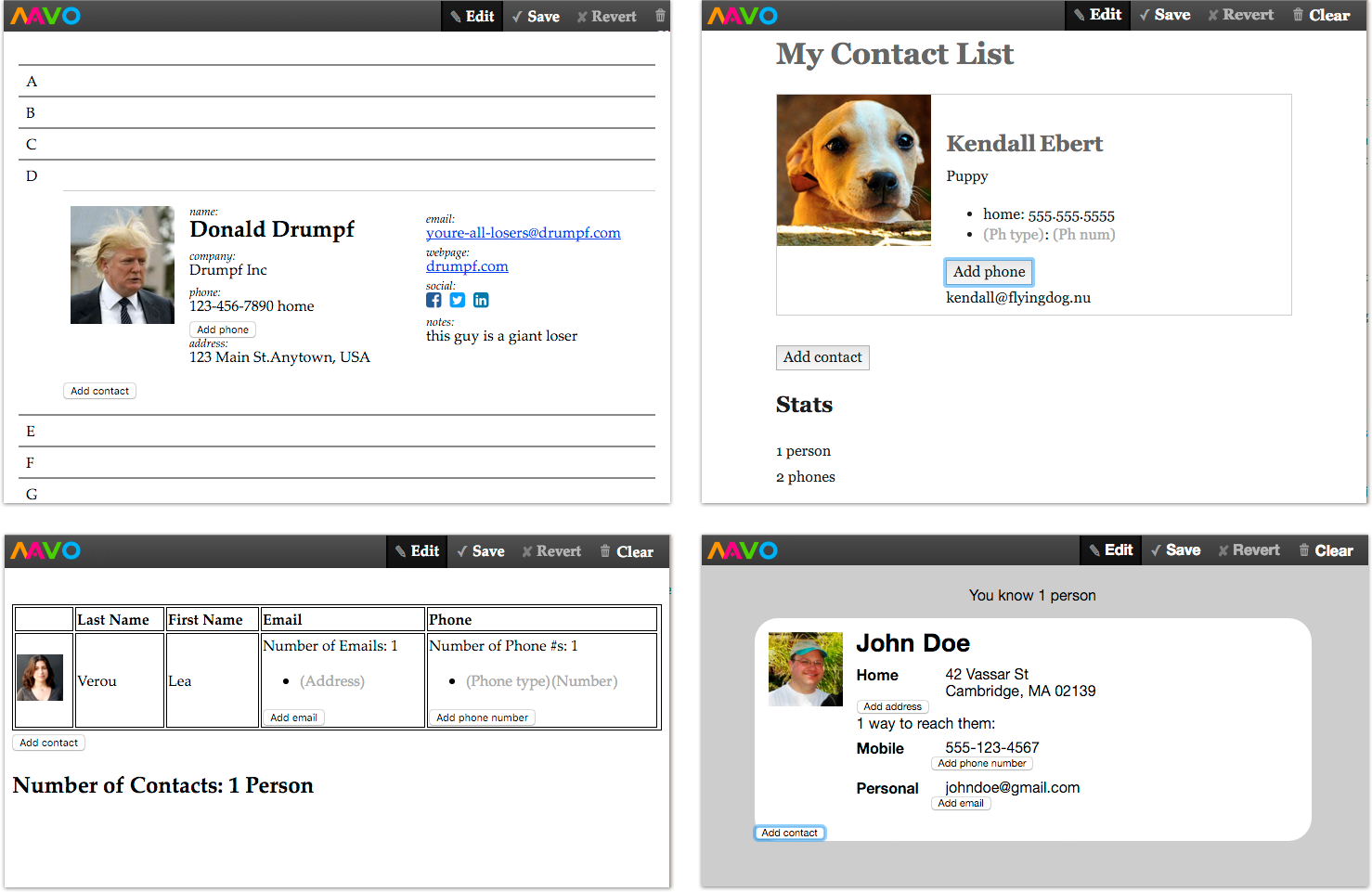
Of our participants, 7 brought in their own static mockup of an Address Book app and had time for the Freestyle study.
We found a variety of implementations of the repeatable contact information portion.
One person used a <table>, with each row representing a different contact.
Three people used <ul>, with each contact as a separate list item, and the information about each contact represented inline or as separate <div> elements.
Two people chose to only use nested <div>s, with each contact having their own <div>.
Finally, one person chose to create a series of 26 <div>s, each one a letter of the alphabet, with the intended ability to add contacts within each letter.
A sample of Own Address Book applications created by users.
When we asked users to use Mavo to improve their mockup in any way, all 7 users chose initially to use the Mavo syntax to
make the fields of the app editable and to support multiple contacts, and had no trouble doing so.
4 out of 7 chose, of their own accord, to support multiple phone numbers, emails, or addresses per contact.
In all but one case, Mavo was able to accommodate what users envisioned, as well as our extra tasks.
In one case (top left in Figure 7.3), the participant wanted grouping and sorting functionality, which Mavo does not support.
She was still able to convert her HTML to a web application, but the user had to manually place each contact in the correct one of 26 distinct “first letter” collections.
A sample of Own Address Book applications that users created are shown in Figure 7.3.
Five more participants brought Contact Manager mockups, but did not have time to animate them due to participating in the Structured study first.
However, all five mockups were suitable for Mavo and followed the same patterns already observed in the Freestyle study.
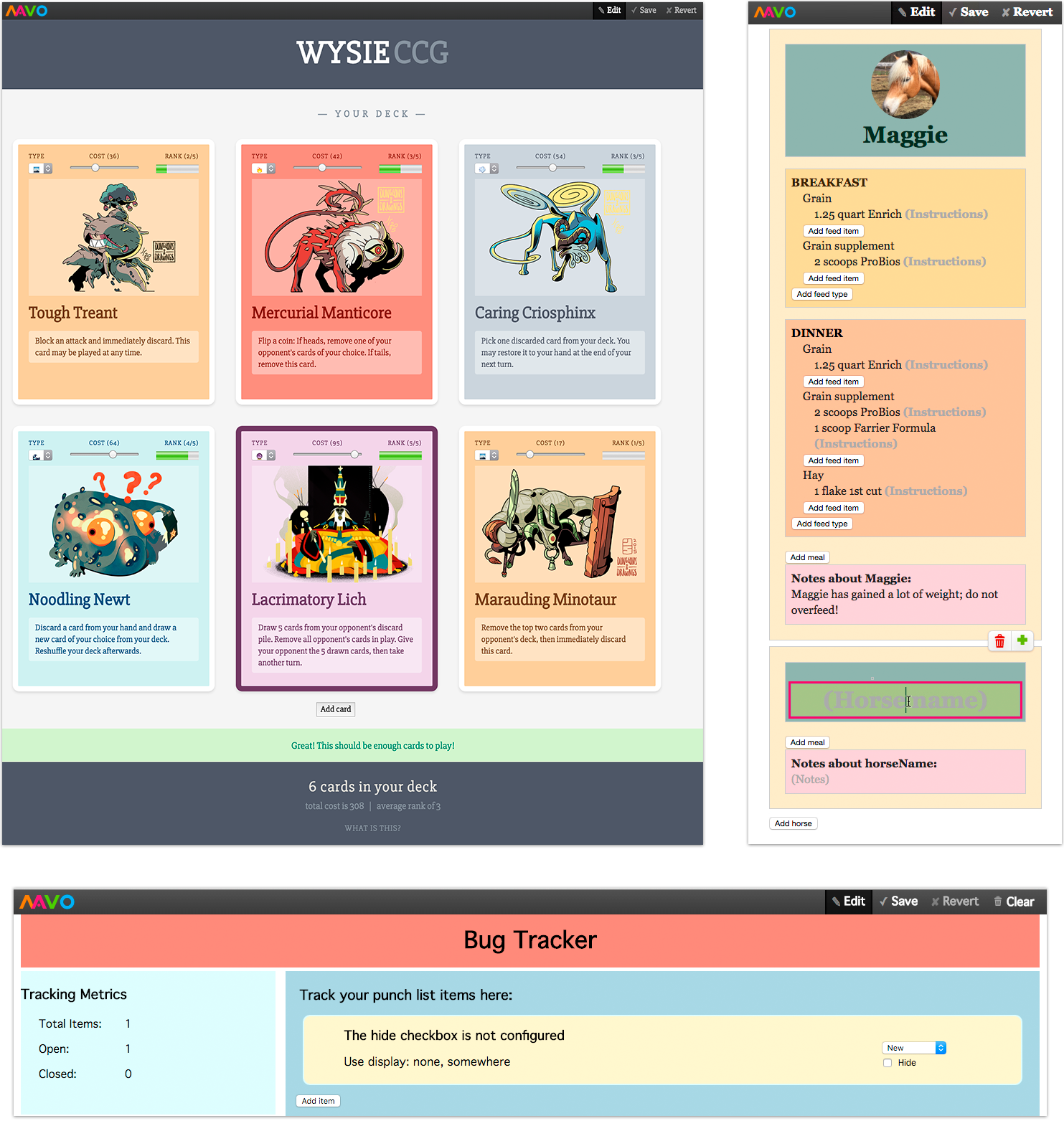
Mavo apps independently created by participants.
Clockwise: Collectible Card Game, Horse feed management, bug tracker.
To further investigate its appeal, we encouraged participants to try out Mavo on their own time after the user study.
Three of them went on to create Mavo apps for their own needs:
(a) a collectible card game, (b) a bug tracker,
and perhaps the most interesting of all, (c) a horse feed management application (Figure 7.4).
The authors of the first two applications were programming novices, the latter intermediate.
Approximately half (9/20) of our participants did not use spreadsheets frequently (“rarely” or “hardly ever”),
while the rest used them frequently or daily.
And while all users had used spreadsheets and spreadsheet formulas before,
most (12/20) had never used the VLOOKUP() function necessary to do joins in spreadsheets.
While it is a plausible hypothesis that familiarity with spreadsheets would make Mavo or Formula² easier to learn,
we did not observe any difference in outcomes between those familiar with spreadsheets and those not.
Some participants used the Inline debugging tools provided to them while others ignored it,
instead choosing to look at the visual presentation of the HTML to see where they went wrong.
One user even commented out loud that they were not going to look at the debug table at all,
then proceeded to fail on a task where a quick glance would have likely prevented this.
A possible explanation is that novices are not used to looking in a separate place for debugging information.
The debug tables were visually and spatially disconnected from the rest of their interface, especially on (visually) larger objects,
which to some extent violates the direct manipulation principles Mavo was based on.
When they were trying to solve an issue, they were looking at the part of the interface that was supposed to display the result, not elsewhere.
Another possible explanation is that the information density of the table is intimidating to novices.
The users who did look at the debug tables found them useful for spotting spelling mistakes,
missing closing braces or quotes, use of wrong property names, and for understanding whether properties were lists, strings, or numbers.
Nobody experimented with editing expressions in the debug table, and few
participants (15%) used the in-browser development tools such as the console and element inspector.
The overall reactions to Mavo ranged from positive to enthusiastic.
One user who was a programming beginner but used CMSs on a daily basis, said
“Being able to do that…right in the HTML and not have to fool with…a
whole other JavaScript file…That is fantastic.
I can’t say how awesome that is.
I’m like, I want this thing now.
Can I have a copy please? Please send me an email once it’s out.”
Along similar lines, another non-programmer said When is this going to be available? This is terrific.
This is exactly the stuff I have a hard time with.
Many participants liked the process of editing the HTML as opposed to editing in a separate file and/or in a separate language:
“It seems much more straightforward, everything is right there.
You’re not referring to some other file somewhere else and have to figure out what connects with what.
It’s…almost too easy”.
Others liked how the Mavo syntax was reminiscent of HTML:
“It didn’t seem like a lot of new things had to be learned because naming properties was just the same as giving classes and ids.”*
“It’s very simple.
It’s as logical as HTML.
You are eliminating one huge step in coding, the need to call the answer at some point, which is really cool…
Everything is where it needs to be, not in a different place”*.
Other users praised the ability to edit the data from within the browser as opposed to a separate file or data system.
One person said,
“I’m convinced it’s magic to basically write templating logic and have it show up and be editable.
I think there’s a lot less cognitive overhead to direct manipulation on the page, especially for a non-technical user”.
This unprompted recognition of direct manipulation supports our argument that this approach is natural.
Though several users struggled with some of the more complicated tasks around expressions,
all participants easily got the hang of defining a hierarchical data schema within HTML using Mavo.
Several users felt that the Mavo attributes of property and data-multiple were powerful
even without expressions, and mentioned wanting to use these attributes to
replicate functionalities of CMSs that they used.
When asked what applications they could see Mavo being useful for,
users mentioned using Mavo to build a color palette app, a movies-watched log, a basic blog, and an app for tipping.
Two users mentioned using Mavo for putting out surveys and contact forms.
Several mentioned using Mavo to build an online portfolio, with lists of projects.
Many participants were enthused about Formula² expressions, even those who had failed at a few tasks.
One participant said about them:
“It’s simpler than I expected it to be.
My anxiety expects it to be hard, then I just say ‘write what you think’ and it turns out to be right.
It’s very intuitive.”
Another user, after learning about filtered aggregates (e.g. count(age > 5)) said
“It’s so expressive, it tells you exactly what it’s doing!”.
Users struggled with conditionals (if()),
and their struggle multiplied when they were nested.
Part of this was , partly due to syntax — balancing parentheses and commas is hard for novices [4, 5].
There are two ways to address this, not necessarily mutually exclusive:
(a) in Formula², by reducing the need to balance parentheses
(b) in Mavo HTML, by implementing a declarative, HTML-based syntax for conditional logic.
For (a), Formula² could adopt a ternary operator such as if test then value1 else value2
or value if test else value2 which is arguably more readable than the functional syntax for everyone.
For (b), Mavo HTML did adopt a declarative syntax for conditionals,
by adding an mv-if attribute whose value is always interpreted as an expression.
in addition to the functional syntax.
count() is the only aggregate function that is meaningful for any data type.
All others (sum(), average(), median(), min(), max()) are only meaningful for
numbers, booleans (treated as 0 or 1), or strings containing numbers.
Using them with lists of objects does not produce an error,
since non-numbers are simply ignored, but it also does not produce a meaningful result.
In tasks where participants had to sum properties of objects in a list (e.g. summing the weights of pros and cons in the Decisions app),
some tried using sum() on the list of items, rather than the list of numbers (e.g. sum(pro) instead of sum(pro.weight)).
Others used sum() instead of count() to count the number of items in a list.
In both cases, all values passed were ignored and the result was 0.
It is an open question how numerical aggregates could be generalized in a way
that produces a more meaningful result when used with objects.
One way would be to look in the object’s properties and operate on all of those that are numbers.
This would enable our participant attempts to write things like sum(pro) to work as expected.
While a useful behavior in its own right, when author intent is to actually sum multiple object properties,
when it is the result of a slip, it could be quite fragile:
you add a property to your schema and suddenly your sum changes!
Another option is to treat objects and other non-numbers as 1 in order to have sum generalize count.
This would eliminate the second type of mistake, but it could be surprising as a general behavior,
whereas descending to object numerical properties seems more inline with Formula² aggregation semantics.
While participants were enthusiastic about the potential of building apps with Mavo, there were also a few requested use cases that Mavo cannot presently accommodate.
Sorting, searching and filtering were recurring themes. Simple filtering and searching is already possible via expressions and CSS, but not in a straightforward
way. We plan to explore more direct ways to declaratively express
these operations. Since Mavo makes collections and properties
explicit, it doesn’t take much more syntax to enable
sorting and filtering of a collection on certain properties; however, the more complex question is to develop a sufficiently simple language that can empower users to fully
customize any generated sorting and
filtering interfaces beyond simple skinning.
One user wanted to filter a list based on web service data (current temperature).
Mavo can already incorporate data from any JSON data source, so this will become possible once we support
combining data from multiple Mavo instances on the same page.
After learning about conditional counting (e.g. count(score > 0),
one participant inquired about more complex queries,
such as counting a different property than the one filtered.
The syntax we are considering for this is optional extra filtering arguments on all aggregate functions.
This would enable syntax like count(gender == female, age > 40, height > 160).
Following the introduction of data update actions,
together with several Formula² improvements,
we conducted a second lab study focused on the usability of these additions.
While data update actions were the focus of this study,
it also serves as another evaluation for Formula² and Mavo HTML,
especially around Formula²’s scoping and referencing,
and its data specification and filtering mechanisms,
which were new additions.
To design a data update language that feels natural to novice programmers, we took a two-pronged approach.
First, we attempted an unconstrained elicitiation [6] of a syntax that users find natural.
Second, we used our prototype language in a constrained elicitation, as we expected different insights from unconstrained responses compared to a prototype.
Several studies [7, 8] have investigated and tried to understand what is natural for novices, by examining the ways that non-programmers express solutions to common programming tasks.
We decided to follow a similar, albeit slightly modified approach.
First, we authored static web page of a simple Mavo application, and we asked our participants to create their own syntax (what feels natural to them) to answer a series of Mavo data mutation tasks.
This study focused on understanding the mental models that novices build about the notional machine.
Second, we went over Mavo’s data actions documentation with the participants, then asked them to write the syntax for the same series of tasks we have asked them in the first part of the study, except now they know the syntax of Mavo’s data actions.
Third, we authored static web page mockups of two representative CRUD applications and then gave users a couple of Mavo authoring tasks that gradually evolved those mockups into complete applications.
Finally, freestyle study, before telling users about Mavo’s data actions (so that they would not feel constrained by the capabilities of our new data mutation syntax), we asked them to create their own mockup of a shopping list application.
In the last three sections, the study focused on the usability and learnability of the data actions syntax.
Is our syntax intuitive and can it be learned in a short amount of time?
What syntax feels most natural to novice web authors for expressing a variety of data mutations on nested data structures?
Is our syntax intuitive and can it be learned in a short amount of time?
We recruited 20 participants (age μ=36.2, σ=9.25; 60% female, 40% male) by publishing a call to participation on social media and local web design meetup groups.
Their (self-reported) skill levels in HTML and CSS ranged from beginner to expert, but intermediate or below in JavaScript.
11/20 described themselves as beginners or worse in any programming language, while 9/20 were intermediate.
Regarding data concepts, 5/20 stated they could write JSON, 4/20 could write SQL, and none could write HTML metadata (RDFa, Microdata, Microformats).
We asked our participants to read through the Mavo Primer2mavo.io/docs/primer and optionally to create a shopping list application with Mavo before coming in for the study.
Sessions were conducted one-on-one, in person and were limited to 90 minutes.
Participants were shown a Mavo application with two collections (men and women) each containing a name, an age and a collection of hobbies (Figure 7.5).
We decided on this schema because it is nested, and the properties have an obvious natural meaning.
The people application, used for a variety of tasks
We used the Mavo Inspector (Figure 3.6) to demonstrate the application in general and in particular the difference between referring to property values within the scope of a collection item versus outside the collection (See Section 4.4.1)
First, participants were asked to write expressions that compute counts for five questions of increasing difficulty,
starting from the simplest (“Count all men”) down to filtered counts (e.g. “count women older than 30”, “count women who have ‘Coding’ as a hobby”, etc),
which participants found problematic in the first Mavo study.
Participants were discouraged from iterating on their expressions, and were told we wanted to capture their initial thinking.
The purpose of this part of the study was three-fold:
(a) to assess their understanding of existing Mavo capabilities,
(b) to verify whether filtered counts were indeed harder, and
(c) to prime them into thinking in terms of declarative functional expressions for the study that was yet to follow.
Not all five questions could be answered entirely with information from the Primer.
For example, the primer did not include the dot notation for narrowing down references
(e.g. woman.age to get ages of women instead of age which would return ages from both men and women).
#
Question
Type
1
Delete all men
delete
2
Add new man (with no info filled in )
add
3
Delete all people
delete
4
Add a new man and a new woman
add
5
Delete current man
delete
6
Make current man 1 year older
set
7
Make everyone 1 year older
set
8
Set everyone’s name to their age
set
9
Delete women older than 30 years old
delete
10
Move the current woman to the collection of men
move
11
Add a woman with the name “Mary” and age of 30
add
12
Add a woman with the name “Mary” and age of 30 to the beginning of the women collection
All 17 data manipulation questions.
The third column indicates whether filtering was needed to answer the question.
The second part was a natural programming elicitation study [6].
We briefly explained the problem that Mavo data updates are solving, as well as our idea for addressing it on a high level.
More specifically, we mentioned the mv-action attribute, as well as the set(), delete(), add(), and move() functions, but presented this as ideas whose syntax we are not sure about and had not developed yet.
We then asked participants to answer 17 data update questions of increasing complexity (Table 7.5) by writing the syntax that felt more natural to them.
They were also encouraged to even use different function names, if that felt more natural to them.
After this stage, we revealed our language prototype so that they could experiment with it during the study.
After a brief tutorial (5-10 minutes), participants had to answer the same questions, in the same order, using our syntax.
After this section, participants were asked to choose 4 questions, one from each action type (set, add, move, delete) and try them out as a training task for the next part.
Researchers would alert them to any mistakes and help correct them.
The final part of the study consisted of two sets of hands-on tasks where participants would try authoring data updates to complete the functionality of two different applications using our syntax prototype.
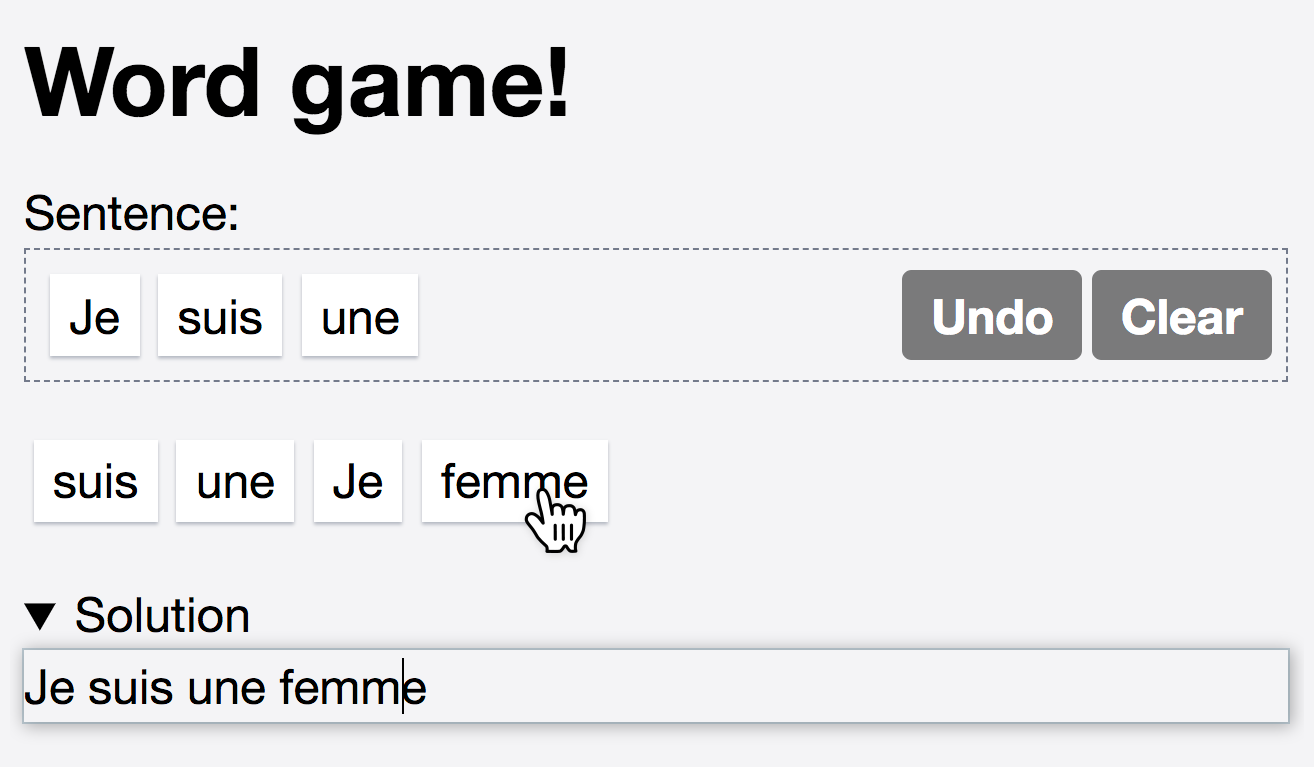
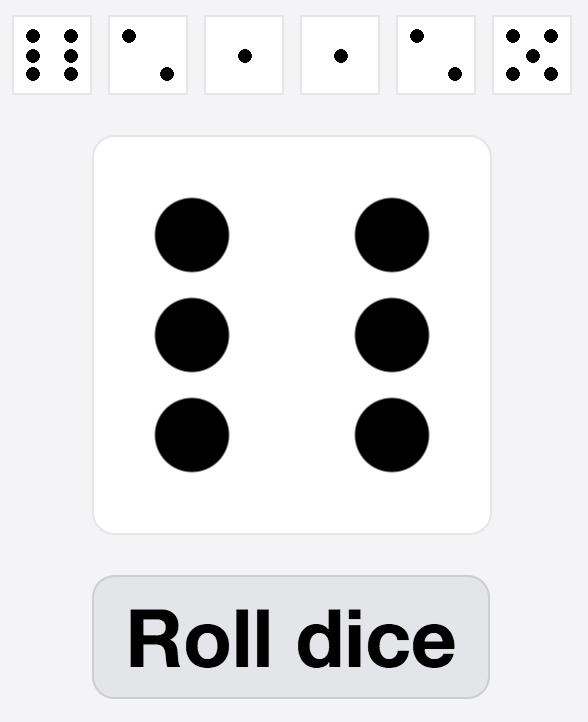
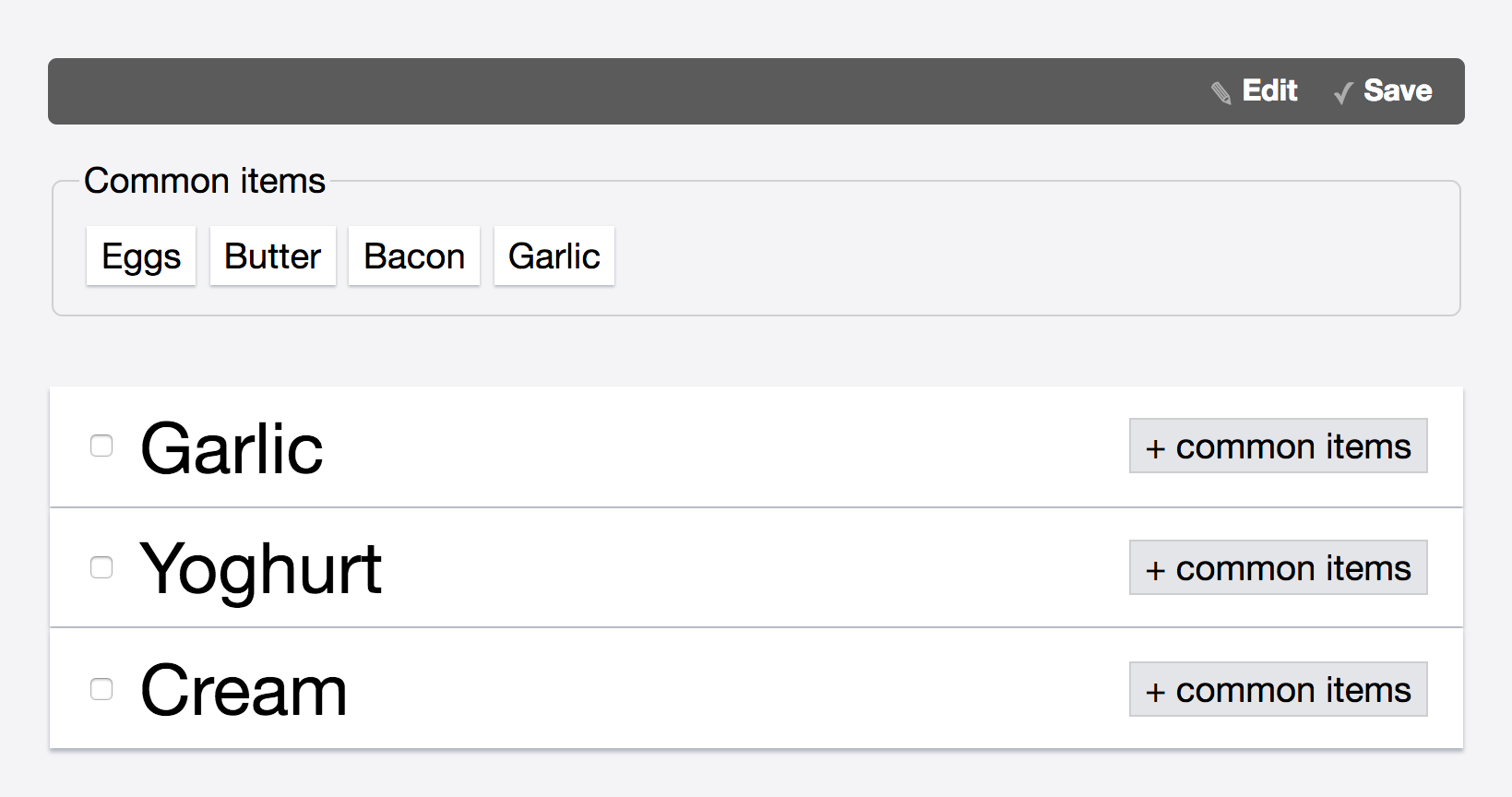
For the first set, participants were randomly assigned one of two applications: a Dice Roller application with a history of past dice rolls, and a language learning Word Game where users click on words in the right order to match a hidden sentence, both having three tasks.
The second set was the same for all users and extended a shopping list application, either one they made, or our template.
For all hands-on tasks (Figure 7.6), participants were given the HTML, CSS and (original) Mavo markup, and only had to add mv-action attributes to complete their functionality.
<fieldset><legend>Common items</legend><divproperty="common"mv-multiplemv-action="add(item, common)"></div></fieldset><ul><liproperty="item"mv-multiple><inputtype="checkbox"property="bought"><spanproperty="name"></span><buttonmv-action="add(common, item)">
+ common items
</button></li></ul>
Figure 7.6
The hands on tasks with their solutions.
From top to bottom: Words game, Dice Roller, our Shopping List (for participants who did not bring their own).
After finishing all tasks, participants were asked a few questions about their experience in the form of a brief semi-structured interview, completed a SUS [9] questionnaire, and a few demographics and background questions.
While participants generally understood properties, groups, and collections,
many participants were confused by the fact that no element in the HTML represented the actual collection,
it was instead a data node that existed purely in the Mavo tree.
This partly motivated changing the collection specification syntax from the original mv-multiple to mv-list/mv-list-item
shortly after the study,
in addition to the many conceptual issues with the original design (discussed in Section 3.3.3.3.1).
All participants correctly answered all Formula² counting questions,
even when they had to count a deeply nested property,
such as counting all hobbies from outside both collections of men and women.
Also, they seemed to have no trouble with filtered aggregates like count(age > 3)
with 17/20 getting them right, and the remaining three making only minor syntax errors.
Participants had some trouble disambiguating between nested properties with the same name across two collections
(e.g. getting only women’s ages or only men’s hobbies).
Like SQL, Mavo uses dot notation for this (woman.age only returns women’s ages), which only 8/20 participants used.
However, as there was no example of this in the Mavo Primer, we did not consider these failures a sign of poor understanding of Mavo functionality.
In this part of the study, we wanted to explore what syntax participants found natural, with the only suggestion being that they had to use the four functions (set, add, move, delete).
This suggestion was introduced to put participants in the mindset of writing expressions instead of purely natural language.
They were even encouraged to use different function names if they wished to, and 6 did so at least once (half of them inconsistently).
Despite emphasizing that constraint, 6/20 participants did not use any functions in at least one question,
but wrote statements instead (such as age = age + 1)
and 4 more used a hybrid approach, with some parameters outside the function call, such as add(woman) name=Mary age=30.
The median time each participant spent answering each question was 28.5 seconds.
As mentioned in Chapter 4, in Formula² expressions, property names can be used anywhere and resolve to the local value or all values depending on the expression placement, enabling very concise references for common cases (see Section 4.4.1).
Thus, delete(man) used “inside” a particular item in a collection of man objects would delete only that item,
while delete(man) “outside” the collection would delete all those man objects.
However, in their own syntax, many subjects wanted to make this distinction explicit.
8/20 used a keyword or function to refer to all items (e.g. man.all) at least once, and 8/20 used an explicit keyword or function for the current item, such as woman.current or this.
Only 3 participants did both.
Interestingly, none followed their own referencing schemes consistently, using these explicit references only in some of the questions or some of the arguments, and plain property names elsewhere.
This may indicate one reason why this referencing scheme is useful: it eliminates error conditions.
More work is needed to understand why our subjects attempted this more verbose language when the more concise one would work.
Based on participant answers to probing questions, the survey format may have played a role: they were writing their answers in text fields, separately from the HTML, so the context of their expression was removed.
In that setting, it may have been jarring to write the same expression as an answer to completely different questions (e.g. “Delete all men” and “Delete current man” are both delete(man) with our syntax).
Perhaps if they’d been writing Mavo expressions inside actual HTML, the disambiguation through context would have eliminated the desire to disambiguate through syntax.
Another possibility is that novice programmers prefer verbosity.
Pane et al. [7] showed that 32% of non-programmers constructed collections by using the keywords every or all.
The use of such verbose syntax could be seen as a form of commenting, adding clarity over more concise code.
It is easy to provide syntactic sugar to allow such explicit references.
In fact, Mavo already defines special all and this variables that work in a similar way although we did not mention this.
We also observed the reverse, of users trying to be more concise.
7/20 participants indicated that the target of their action is the current item by omitting a parameter, such as writing delete() for deleting the current item or move(man) for moving the current woman to the collection of men.
Stylistic choices such as punctuation should be distinguished from expressions which must be regarded as incorrect because they are missing necessary information for the operation.
However, even in those cases, it is hard to be certain that there is a logic error at play.
Are the missing parameters actually missing, or did the participant have a clever heuristic in mind for inferring them?
And if not, is it a logic error, or merely a slip?
In this section, we describe some of the most common patterns of (ostensibly) underspecified expressions that we observed.
By far the most common one was delete(<predicate>) with no reference to the item(s) to be deleted.
For example, delete(woman.age > 30) for deleting women older than 30,
or delete(hobby = Dining) to remove the hobby “Dining” from all people.
18/20 participants did this at least once, and 10 did so in both of the conditional delete questions (Q9, Q13).
One possible interpretation could be that in their mental model,
specifying the target of the operation is only necessary for disambiguation —
when the expression only includes one data reference, what else could we be targeting?
Another common pattern was using set(age + 1) to increment all ages.
15/20 participants used a variation of this syntax.
This is consistent with the proposed interpretation above,
that when there is only one data reference, they expect the update target to default to it.
As further evidence for that theory, there was no such underspecification in Q8 (Set everyone’s name to their age), which involved two properties.
None of the participants realized the inconsistency when they answered the latter and did not think to back and change their answer to the former.
Asking a subset of participants about this at the end revealed that some thought that age + 1 would function as an increment operator (like C’s age++).
Both patterns indicate a distaste for parameter repetition, which on par with natural language:
“parameters” are only explicitly specified when different and are otherwise implied.
5/20 participants wrote their expressions as if the “name” property was special, i.e. was an implied primary key.
For example they would use the identifier Mary to refer to the person that has ``name = “Mary”`,
without specifying “name” anywhere in their expression.
This did not seem to correlate with a lack of (self-reported) programming skill,
as only one of them had not been exposed to programming at all.
It is unclear whether this has to do with the word “name” itself, or with the fact that names were indeed unique in the data we gave them.
Using objects as numbers was common, e.g. omitting “age” from delete(woman > 30) or set(man + 1).
Many participants attempted it at first, and 4/20 submitted their answers with it.
In many cases this turned out to be a slip,
but two participants articulated a consistent mental model:
it automatically operates on all numeric properties!
In Pane et al. [7], 61% of non-programmers modified the object itself instead of its properties,
which is even higher than the percentage we observed.
While commas are likely the most widely used argument separator, they did not appear to be very natural to our subjects.
7/20 did not use any commas, but instead separated arguments by other symbols, or even whitespace.
5/20 only used commas for repetition of the same argument type (e.g. delete(man, woman)).
From the remaining 8 subjects, only 2 used commas exclusively to separate arguments.
The rest combined commas with separators that were more related to the task at hand.
16/20 subjects used = to separate arguments at least once, most commonly in set().
9/20 used to, primarily in set() and move().
Other separators were used by 3 people or fewer (whitespace: 3/20, colons: 3/20, parentheses: 1/10).
Only 8/20 participants used multiple function calls in an expression (such as add(man) add(woman))
The rest tried to express compound actions via arguments of one function call (such as add(man, woman)), even when this was inconsistent with their later responses.
In spreadsheets (like Formula² before data update actions),
expressions have no side effects and only produce one output, therefore there is never a need for multiple adjacent function calls
Therefore, using more than one function call may feel foreign and unnatural to these users.
In the prototype syntax, we had used different punctuation (period, comma, colon, semicolon, and spaces) to separate the key from its value, the object from its properties, different collection or items, and different functions.
For example, for one of the questions that we asked our participants (add a new man and a new woman),
the prototype syntax expected separate functions add(man) add(woman),
which could be separated by spaces, commas, or semicolons.
In another question where we asked our participants (Set everyone’s name to their age), the answer should be set(name, age), the two properties, the key and the value here, should be separated by comma, But 12/20 of our participants used = to separate the key and the value in the function set()
ON the other hand, in the move() category questions (e.g. Move the current woman to the collection of men),
9/20 participants used the keyword to, so instead of writing move(woman, man) they wrote move(woman to man).
Four questions required filtering on a collection (cases where a corresponding SQL query would need a WHERE or HAVING clause)
to specify the target of the data update.
For example Delete women older than 30 years old (Q9),
requires some way to filter the collection of women by age, then delete all matched items.
Our prototype syntax supported this kind of filtering with a where operator,
so woman where age > 30 would produce a list of women whose age is over 30.
Half of our participants also defined a language-level filtering syntax, such as if or where keywords, or parentheses (e.g. woman(age>30))
whereas 6/20 expected that the data update functions would allow a filtering argument.
However, if appeared to be a slightly more natural keyword for our participants,
with 5/20 using it at least once in these tasks, in contrast to 3/20 using where.
5/20 used filtering by predicate (e.g. delete(woman.age > 30)),
4/20 used filtering by parentheses, and 6/20 used filtering by argument.
5/20 expected that predicates would act as a filter of the closest collection item and consistently used them in that fashion
For example, they expected that man.age > 40 would return a list of men whose age was larger than 40, and wrote expressions like set((man.age > 40).name to "Chris") for Q16
However, in Mavo currently the inner expression returns a list of booleans corresponding to the comparison for each man.
Participant free-form syntax was consistent with our current prototype syntax (would have produced the correct result) with no changes in 4.35/17 answers on average
(σ = 2.16) and with minor changes (different symbols or removing redundant tokens) in 8.6/17 answers on average (σ = 2.06).
Some questions were asking about multiple operations of the same type, to examine whether participants will use
separate functions in the same action (e.g. delete(man), delete(woman),
or one function with separate multiple arguments (e.g. delete(man, woman)).
Our prototype syntax supports that kind of aggregation for delete(), because deleting an item does not require any other parameters.
However, it cannot as straightforwardly be supported in add(), as it supports specifying other parameters for the new item.
We were curious to see if our participants will be able to draw this kind of distinction by themselves.
From our survey, we found that 9/20 participants used separate functions in general, and 7/9 who used separate functions used them in the case of adding a new man and a new woman
However, 13/20 used one function (e.g. add(man, woman)
It was also interesting to notice that only 3/20 used a separate functions for delete all man and women, which also works
But 4/7 participants who used separate functions for adding a new man and a new woman mv-action="add(man), add(woman)") did not use separate functions for delete all men and woman mv-action="delete(man, woman)").
In the survey, we have asked our participants a couple of questions about moving an item to the beginning of its list
(e.g. Move the current woman to the beginning of the women collection — move(woman, 0) in our prototype syntax).
We wanted to understand how non-programmers would define “beginning”.
Would they use a numerical index or a keyword?
If a numerical index, would they use 0 or 1?
If a keyword, would they use start, top, or something else?
8/20 used the number 0, 3/20 used number 1, 3/20 used the keyword first, 2/20 used the keyword top,
and interestingly, others assumed that moving an item to the top of its list would be the default behavior if no position was specified (e.g. move(woman)).
In this part, we revealed our syntax prototype to participants and asked them to answer the same questions, but this time using our syntax, to test the learnability and usability of our prototype.
Participants were not allowed to test their expressions, and were discouraged from iterating as we wanted to capture their initial thinking.
Therefore, correct answers in this section are equivalent to participants getting the answer right on first try and with no preceding training tasks.
Overall, 11 out of 17 questions had a correctness rate of 75% or above with 8 (Q1-3, Q5, Q8-10, Q17) having 90% or above, i.e almost every participant got them right on first try.
The most prominent patterns from the previous step persisted, though to a lesser extent.
7/20 participants remained unable to use a sequence of two function calls for Q4 despite this being covered in the tutorial, and wrote add(man, woman) or a variation.
Curiously, based on later answers, all seemed to understand that the second parameter of add() holds initial data, yet none realized the inconsistency.
Similarly, 4/20 participants still used set(age + 1) to increment ages, 2/20 used objects as numbers, and 8/20 used delete(``<predicate>``).
Almost all failures in add with initial data questions (Q11-12) were related to grouping the key-value pairs,
or incorrectly using equals signs (=) instead of colons (:) to separate them.
Two questions asked participants to delete items with a filter, but had vastly different success rates.
18/20 participants got Q9 correct, while only 9/20 got Q13 right, despite the superficial similarity of the two questions.
The difference was that Q9 was operating on a list of primitives, so the values being deleted were also the same values used for filtering.
It felt normal to write something like
Participants had a very hard time using hobby twice in Q13 (The correct answer is delete(hobby where hobby = ’Dining’) and even those that got it right hesitated a lot before writing it.
By far the hardest questions were Q14 and Q16, where participants had to filter on one property and set another.
Only 7/18 of participants answered them correctly.
All knew which function to use, and almost all used where correctly for filtering, but were then stuck at where to place the property they were setting.
In Q14, a common answer was set(man where age > 40, "Chris").
Users when then unsure where to put name.
The correct syntax in this case (if using where) would have been set(man.name where age > 40, 'Chris'),
which is indeed confusing as one would expect the property being set to be grouped with its value, not with the filtering predicate.
For the add() category, we asked them several questions (e.g. Add a new man, Add a woman with the name “Mary” and age of 30, etc) that varies in their difficulties.
76.25% of participants answered these questions correctly on first try.
We noticed that 81.67% of participants answered the questions that asked them to deal with one collection, man or woman,
(e.g. Add a woman with the name “Mary” and age of 30),
but only 60% of them answered the questions asking them to deal with both collections, man and woman, (e.g. Add a new man and a new woman).
Even after seeing examples of this when shown the prototype syntax they still were unsure if they can write two functions in mv-action
(e.g. mv-action="add(man) add(woman)").
7/20 of participants still added both man and woman in the same function (e.g. mv-action="add(man, woman)").
For the delete() category, we asked several questions that varies in difficulties as well (e.g. Delete all men, Delete women older than 30 years old, etc).
83% of participants solved the questions in this category correctly from the first try.
In this category, for the questions that include conditions (e.g. Delete “Dining” as a hobby from everyone), we found that they were more challenging for our participants than other questions that do not include conditions (e.g. Delete all people).
93.33% of participants solved the questions without conditions correctly and only 67.50% of them solved the ones with conditions.
For the questions with conditionals (e.g. Delete “Dining” as a hobby from everyone), there were confused about hobby where hobby in delete(hobby where hobby= "Dining")I need to say why?
The set() category was the most challenging category for our users.
In total, only 59.56% answered the questions in this category correctly.
And like the delete() category, we had two different sets of questions.
Some with conditions (e.g Rename every man with age > 40 to “Chris”) and others without (e.g. Make current man 1 year older).
73.33% of participants solved the questions without conditions correctly, however, only 38.89% solved the ones with conditions correctly.
For example, for the question (Make current man 1 year older), the right answer is set(age, age+1), nevertheless, our participants were confused about how the set function works.
They thought that they can just send the new value, without specifying what to set it to, for example, some of our participants thought that set(age+1) will automatically increase the age by one, others though that setting age+1 to the man would be sufficient to increase the man’s age by one.
Same thing with another question we asked them (Rename every man with age > 40 to “Chris”), they did not know what to set the name to, so they would do something like set(man where age > 40,"Chris") instead of set(name where age > 40,"Chris"), or they would not be sure about the order of setting values and using where condition, so they would do something like set(Set (name, ’Chris’ where age > 40)).
This involved questions such as Move all men to the collection of women (Q17),
or Move the current woman to the beginning of the women collection (Q15).
The category move() unlike set(), was much easier for users to understand.
93.07% of participants solved the questions in this category.
16 participants completed the hands-on section of the study (see Figure 7.6).
Half were randomly assigned to the Dice Roller application, and the rest to the Words Game application.
13 also completed the Shopping List tasks.
All participants solved the first two tasks correctly and were able to display a random dice roll (task 1)
within a median time of 55 seconds and to display it in the history (task 2) within a median time of 70 seconds.
5/8 and 3/8 did so on first try.
5/8 participants hesitated before using multiple function calls in mv-action, even if they had answered Q4 with two function calls in the survey, but they eventually got it right.
The third task was to prevent the current dice roll from showing up in the history.
Despite the second task being carefully worded to avoid implying a particular order, all 8 participants used add() after the set() they had written in the first task.
This places the current die in the history as well as the main display.
The opposite order would have rendered the third task redundant, yet nobody realized this.
Furthermore, only 1 participant was able to solve the third task.
All they had to do was use add() before set(), i.e. swap the order of the two functions.
This would add the dice to the history before they replace its value with a new random value.
None of the other 7 participants was able to figure out why this was happening, nor how to fix it.
Some participants thought that multiple function calls are executed in parallel,
a common misconception of novice programmers [8].
This appears to be a general failure of computational thinking, not specific to Mavo or Formula².
This proved to be substantially easier than the dice roller.
6/8 participants succeeded in all three tasks.
Clicking on words to add them to the sentence took a median time of 3.6 minutes,
deleting the last word (Undo) took 43 seconds, and deleting all words took 2.9 minutes.
For the first task, a common mistake (3/8 participants) was to use move() instead of add() to copy the clicked word into the sentence.
Even after realizing their mistake, they were ambivalent about using add().
The shopping list application with its solution (for participants who did not bring their own)
13 subjects carried out the Shopping List tasks, copying to (task 1) and from (task 2) a “Common Items” collection.
6 participants brought their own application and 7 used ours.
Numbers of participants and median times for each Shopping List task
Almost all participants succeeded in both tasks, with only 1/13 failing the first task and 3/13 failing the second one.
It took slightly longer for participants using their own app to get started on the first task with a median of 133 seconds vs 55 seconds.
By the second task the difference had been eliminated (55 vs 50 seconds).
Three participants were confused about whether to use move() or add() to copy the shopping list item to the common items, but quickly figured it out after trying.
For the participants who used our Shopping List application: For the first task, 6/7 participants solved this task on first try within a median of 55 seconds.
For the second task, also 5/7 solved the task correctly from the first try within a median time of 50 seconds.
1/7 participant was confused on where to add mv-action attribute.
For the participants who used the Shopping List application they created before the study using Mavo: For the first task, 6/6 participants solved it correctly within a median time of 133 seconds.
For the second task, 5/6 were able to solve it successfully within a median time of 55 seconds.
4/5 participants solved from the first try.
At the end of each session, subjects rated their subjective experience on a 7-point SUS scale with 10 alternating positive and negative questions.
The answers were then coded on a 5-point scale and the SUS score was calculated according to the algorithm in [9].
We removed one participant who had selected “Agree” on all 10 questions (positive and negative), indicating lack of attention, a common problem with SUS.
Our raw SUS score was 76.3 (σx̅ = 2.43), which is higher than 77.5% of all 446 studies detailed by Sauro [10]
Our raw Learnability and Usability scores as defined by Lewis and Sauro [11] were 78 and 69.7 respectively.
The overall reactions to Formula² + data mutation functions ranged from positive to enthusiastic.
Several participants remarked on the perceived intuitiveness of the syntax.
One participant answered several questions on the survey in one go, without looking at the documentation,
then paused and said it’s so intuitive, I don’t even need to look at the docs!.
Many other participants remarked on expressiveness;
it is very easy to do complex things!, as one of our participants phrased it.
Most participants described our data update actions as easy, even those who made several mistakes.
Example quotes:
This is very application-centered, a page that can actually do something!.
I think they [data mutation functions] are very useful, easy, and approachable
it is definitely more accessible than having to program, so that’s pretty cool
“They are easier and quicker to make things without worrying about technicality.
It is very easy to use”
As with the first study, many participants liked being able to use this functionality by editing HTML as opposed to editing in a separate file and/or language:
“Interesting to be able to do these things from the HTML!”
“It is interesting!..being able to do this in HTML, I was able to use it pretty easily, once I knew what functions there were and the syntax it has it was very easy.”
Users also liked the fact that they can build applications that typically require programming.
“This is easier than JavaScript! If I wanted to do something complicated I would be frustrated to use JavaScript cause I’m not good at it, this is easier”.
“It’s easier and quicker to make things without worrying about technicality.
It’s very easy to use”.
Several participants commented positively on the where operator.
“the where syntax is like natural language, I did not expect it to be there and written as if I am saying it”.
In September 2020, we contacted Mavo authors we found from website access logs and interviewed five of them about their experiences.
While this never resulted in a published study, a very prominent pattern was present across most interviews:
users generally loved the parts of Mavo that were core to its design: they found the syntax intuitive and the capabilities very powerful.
However, they were having a lot of trouble with superficial aspects of the design and prototype implementation,
the most prominent of which were:
They wanted server-side rendering for their content, not having data fetched client-side
They did not like the loading indicator and found it too intrusive
Performance was slow.
More often than not, these were insurmountable problems to them and eventually drove them away.
For Mavo to gain wider adoption, it is important to invest in addressing such issues,
even if the research value of such work is only in the longer term.
The four apps completed by participants in the Mavo-Shapir study:
(1) Dailymotion playlist viewer,
(2) YouTube video search,
(3) Yelp & Foursquare search,
(4) Event searching app combining SeatGeek, Ticketmaster, Songkick.
Alrashed et al [12] integrated Mavo with ShapirJS, a JavaScript library that
normalizes data from various APIs into schema.org[13] ontologies
and exposes them as live JavaScript objects that can seamlessly perform asynchronous API calls
to fetch additional data and can update remote data via standard JavaScript object manipulation methods.
Combined, ShapirJS and Mavo make it possible to create standalone web applications
that read, combine, and manipulate data over multiple web APIs without writing any JavaScript or back-end code.
Mavo-Shapir was implemented as a Madata backend, and packaged as a Mavo plugin.
To support this integration, Formula2 was extended to support asynchronous values,
which opened up many new possibilities for what Formula2 expressions.
They then evaluated this combined system in a lab study with 16 participants (9 female, ages 18-60).
Of these, 8 identified as beginner or intermediate in HTML, and 8 as advanced or expert.
Their programming skills ranged from none to skilled: 2 with no programming skills, 6 beginners, 6 intermediate and 2 skilled.
In terms of Mavo familiarity, 7 participants had used Mavo before, 4 had heard of it but not used it, and 5 had never heard of it.
Participants were given functional Mavo apps operating on local data, and they had to adapt them to work with live data from various APIs.
All participants were able to complete the tasks in under 4 minutes, with apps 2-3 taking them about a minute on average.
There was no correlation between time taken and programming skill or Mavo familiarity.
Participants were generally very positive about the experience;
they found the combination of Mavo and Shapir easy to use,
and were impressed by how quickly they could build applications that combine data from multiple sources.
Figure 7.9
An artist page made with Mavo and Wikxhibit that displays integrated data from different websites:
general information about the artist from Wikidata, their albums and tracks from Spotify,
their videos from YouTube, and their events from Songkick.
Alrashed et al later integrated Mavo-Shapir with Wikidata,
a free and open knowledge base that can be read and edited by both humans and machines [14]
to create mashups of data from multiple APIs.
Effectively, Wikidata is used as a universal join table to cross-reference entities across different third-party APIs
(see Figure 7.9 for an example).
They then evaluated this system in a lab study of 12 Wikidata users.
Of the participants, 8 identifed as beginner or intermediate in HTML, and 4 as advanced or expert.
Additionally, 7 described themselves as beginners or worse in any programming language, while 5 considered themselves intermediate or better.
Of these participants, 7 participated in the structured study, where they were given static HTML & CSS scaffolding
for three applications, and they had to write Mavo HTML to pull in different data sources and display their data in a suitable way.
After going through a brief tutorial, 6/7 users went on to complete all the tasks for their three applications with no failures (1/7 had to leave early).
They took, on average, 14 minutes (Tech Company, 6 tasks), 9 minutes (US President, 5 tasks),
and 5 minutes (Botanical Gardens, build an app from scratch) to build the entire application.
One study finding relevant to Mavo was that a common slip was participants forgetting to add mv-multiple attributes
and being confused when they could only see one item.
This is part of Mavo’s schema mapping heuristics (Section 3.6.2), to allow seamlessly converting
between scalars and lists without data loss and displaying the same data across different Mavo apps.
However, perhaps mv-path could be used instead to explicitly opt-in to this behavior.
A compromise could be to display all array items, but not add any UI for adding new ones until mv-list-item
(nee mv-multiple) is specified.
Five participants participated in the later freestyle study, creating their own applications from scratch.
All were able to accomplish the applications they set out to build, in less than 30 minutes (3/5 in less than 15).
The applications created included a page about the movie “The Big Lebowski”,
a presentation showing a list of the superior courts of California
a page showing political parties of a user-provided country specifed via an input field,
and an application shows information about comic strips that are part of xkcd3xkcd.com.
The next chapter presents Lifesheets,
whose contribution is twofold:
First, to explore the value and feasibility of empowering end-users to create their own tracking applications,
and second, to expose lightly abstracted Mavo concepts (especially Formula2) to non-programmers via a GUI.
Its user study provides insights on both,
and is described in detail in Section 9.7.
Here we pull in only the high level insights that relate to Mavo concepts.
By exposing forms to generate formula calls we were able to short-circuit many syntax errors,
while still exposing enough of Formula2 to get valuable insights.
Additionally, unlike the previous Formula2 studies, it included a control condition,
where users were also writing spreadsheet formulas for the same tasks
(between subjects on the task, within subjects on the condition).
Overall, the study validated our hypothesis that
novices can largely understand and use Formula2 for grouping, aggregation, and temporal calculations,
and that these tasks are very difficult with spreadsheets.
Despite spreadsheets supporting UI features that make these tasks easier (e.g. data validation, pivot tables),
the fact that these are separate features that users need to know about in practice meant that they were not used.
Instead, users were painfully trying to accomplish these tasks with formulas, until they gave up or did them manually
or semi-manually (e.g. emulating a pivot table via a manual list of values and SUMIF() formulas).
A recurring theme we observed was the end-users’ distaste for indirection.
Participants generally expected to be able to be able to accomplish their goals via a combination of
UI settings, or a single formula call, and continued trying different parameters
until they either got the right result (often as a happy accident rather than an accurate mental model),
or got frustrated and gave up.
While not appearing in this study, there were also use cases that required auxiliary data in Formula2
(which can only be created via the host environment, e.g. Mavo).
A common example is nested aggregates (e.g. average of averages) —
before the in operator, they required a hidden Mavo property and could not be done with Formula2 alone
(see Section 4.7.3).
A big takeaway from the study was that temporal calculations in spreadsheets were extremely painful,
whereas the Formula2 counterpart was generally a lot more understandable.
Perhaps the most characteristic such case is calculating intervals and displaying them in a human readable way (see also Section 4.7.1.3),
for which Formula2 provides a high level primitive.
However, even with Formula2 there were some recurring mistakes that highlight areas for improvement,
mainly around values only being useful when used a certain way, and not another that users tried.
This included:
Attempting to do math with duration() (which returns an array of strings)
Printing out $now and getting confused at the result (a number of milliseconds)
Setting a time property to $now and getting confused that it didn’t work (since it expects a string like "HH:mm", and $now is a number)
These attempts are reasonable things that should and could work if these functions and special properties
return objects that retain their metadata and thus can be used in a variety of ways,
rather than primitives like numbers of strings.
Mavo HTML was more highly abstracted, and thus many study findings are less directly applicable to it.
However, there were still some insights that are relevant.
The biggest issue was related to Saving.
Having to click a Save button to persist their data felt foreign to users, who expected their data to be saved automatically.
While Mavo supports an mv-autosave attribute, it is discouraged for backends that
save to version control systems, in order to maintain a meaningful edit history (which can later be exposed via a UI).
Perhaps a best of both worlds approach could be to autosave to a local storage,
that is periodically synced to the VCS.
Placeholder entries (which Mavo automatically creates unless mv-initial-items="0" is used)
seemed natural while the application was being built,
but baffled users when they attempted to use the deployed application for the first time.
Verou, L., Zhang, A.X. and Karger, D.R. 2016. Mavo: Creating interactive data-driven web applications by authoring HTML. UIST 2016 - Proceedings of the 29th Annual Symposium on User Interface Software and Technology (2016), 483–496. 10.1145/2984511.2984551.
Cited in1
Jackson, D. 2015. Towards a theory of conceptual design for software. 2015 ACM International Symposium on New Ideas, New Paradigms, and Reflections on Programming and Software (Onward!) (New York, NY, USA, Oct. 2015), 282–296. 10.1145/2814228.2814248.
Cited in1
Ma, L. 2007. Investigating and Improving Novice Programmers’ Mental Models of Programming Concepts (Doctoral dissertation, University of Strathclyde).
Cited in1
Kelleher, C. and Pausch, R. 2005. Lowering the Barriers to Programming : a survey of programming environments and languages for novice programmers. Science. 37, (2005), 83–137. 10.1145/1089733.1089734.
Cited in1
Myers, B.A., Ko, A.J., Latoza, T.D. and Yoon, Y. 2016. Programmers Are Users Too: Human-centered methods for improving programming tools. Computer. 49, (2016), 44–52. 10.1109/MC.2016.200.
Cited in1, and
2
Pane, J.F., Myers, B.A., and others 2001. Studying the language and structure in non-programmers’ solutions to programming problems. International Journal of Human-Computer Studies. 54, (2001), 237–264. 10.1006/ijhc.2000.0410.
Cited in1,
2, and
3
Ma, L., Ferguson, J., Roper, M. and Wood, M. 2011. Investigating and improving the models of programming concepts held by novice programmers. Computer Science Education. 21, (2011), 57–80.
Cited in1, and
2
Brooke, J. 1996. SUS: A “Quick and Dirty” Usability Scale. Usability Evaluation in Industry. 189, (1996), 4–7. 10.1201/9781498710411-35.
Cited in1, and
2
Lewis, J.R. and Sauro, J. 2009. The factor structure of the system usability scale. International conference on human centered design (2009), 94–103.
Cited in1
Alrashed, T., Verou, L. and Karger, D.R. 2021. Shapir: Standardizing and Democratizing Access to Web APIs. The 34th Annual ACM Symposium on User Interface Software and Technology (Virtual Event USA, Oct. 2021), 1282–1304. 10.1145/3472749.3474822.
Cited in1
Alrashed, T., Verou, L. and Karger, D. 2022. Wikxhibit: Using HTML and Wikidata to Author Applications that Link Data Across the Web. Proceedings of the 35th Annual ACM Symposium on User Interface Software and Technology (New York, NY, USA, Oct. 2022), 1–15. 10.1145/3526113.3545706.
Cited in1