Most Web users have needs beyond what commercial web applications support.
Automating common tasks, storing arbitrary data and performing calculations on them,
tracking, are only a few categories of use cases.
Despite the Web originally being designed so that anyone could contribute, not just passively consume [1],
these days the Web Platform1The set of technologies used to develop web applications, see en.wikipedia.org/wiki/Web_platform has grown tremendously in both complexity and power.
It now takes years of training for someone to be in a position to create bespoke web applications,
and even professional programmers with years of experience often lament the complexity of the modern web stack.
Even though trained programmers have the ability to create web applications for their own needs,
the task is still so laborious, they rarely embark on it.
The goals of my research are three-fold.
The primary goal is to make web application development accessible to a wider audience and bring it within reach of everyone.
A secondary goal is to make it faster for any audience. If trained programmers can create prototype applications really fast, everyone wins.
Lastly, a tertiary goal is to contribute towards increasing the amount of machine-readable data on the Web and towards decentralization,
not by attempting to convince users that these are worthy goals, but by creating technologies that incorporate them as a natural part of the interaction that does not require additional effort or even interest from the end-user.
Few questions fill web practitioners with more dread than a variation of
this deceptively simple query:
"I want to publish a simple personal website and be able to easily edit its content.
Nothing much, just a bio, a portfolio, and a contact form.
I can’t afford to hire a web developer, but I’m a little technical, I think I could do it.
What tools would you recommend?
The reaction is typically a deer-in-the-headlights look,
as if having explain to a small child that puppies die sometimes.
It is true that a multitude of tools and services exists,
but answering the question is less about picking the best tool for the job,
and more about scrambling to figure out the lesser of many evils.
Social media services (e.g. Facebook or Medium) are likely the lowest threshold (see Section 1.4.1) solution,
but also come with a very low ceiling.
They afford no control over presentation,
and data schema and storage is entirely controlled by the service provider.
Similar downsides apply to website builders like Wix or Squarespace, though to a lesser extent.
Content Management Systems (CMSes) are meant to be a middle ground between the lack of control of centralized services
and the complexity of writing a web application from scratch
but are associated with high levels of dissatisfaction [2]:
they still require a lot of technical skill to set up and maintain,
they are bloated and heavyweight for most use cases,
yet still too rigid for many common use cases.
On the other end, the highest ceiling solution is to write a web application from scratch.
However, even for more technical users, this is a daunting task.
Even a deceptively simple website like the one described above would require a lot of code,
and deep understanding of many technical concepts such as
authentication, templating, sending and receiving HTTP requests,
data binding, handshakes, asynchronicity, security, and many more.
Despite the Web being originally envisioned as a read-write medium [1, 3],
web publishing today suffers from numerous usability cliffs (see Section 1.4.2).
Beyond publishing content, many users have data management needs that cross into the realm of web applications,
requiring not just data binding, editing, and persistence, but also computation and interactivity.
Examples abound: managing tasks, expenses, recipes, tracking life events,
calculating interest rates and loan payments,
or even more complex use cases like managing a small business or a community,
to name a few.
Some of these use cases are common enough to make business sense for launching specialized commercial applications,
but others are part of the very long tail of use cases that too niche to be served by commercial applications individually,
yet vast in aggregate.
Even for use cases that on the surface appear to be well served by commercial applications,
user needs are also varied and often not fully met by one-size-fits-all solutions.
For example, let’s take a simple use case like tracking household expenses.
Some families have joint finances, others keep them separate.
Some of the latter split expenses evenly, others proportionally by income, and others anywhere in between.
Some families only need to deal with one currency, others travel enough that currency conversion is a frequent concern.
Prefabricated applications either only deal to the subset of these needs that are most frequently encountered
(known in product management as the 80/20 Pareto Principle [4]),
or grow to enormous complexity (feature creep) if they try to cater to all of them.
While avoiding feature creep is generally good, it does mean that the resulting applications skew toward mainstream needs,
and often leave minorities behind.
The main alternative to prefabricated applications is to build one’s own tools.
Unlike the web publishing use cases, users rarely ask deceptively simple questions about this —
they simply assume that building high fidelity tools for their needs is out of reach.
When the delta between their needs and those catered by the prefabricated options,
they typically try to adapt them to the tool.
When it is too large, they resort to no-code tools such as spreadsheets, which do help with data management and lightweight computation,
but are very limited in terms of presentation and interactions
and many users struggle with authoring and debugging formulas [5, 6].
Creating websites and creating web applications is often treated as two distinct use cases,
but the line between them is blurry.
The need to manage structured data and share and display them on a webpage is very common.
Consider a personal website displaying a portfolio, or a list of publications, speaking engagements, press mentions.
Or a restaurant needing to manage and display their menu with dishes, prices, categories.
Or a real estate website displaying listings of available properties.
Or a wedding website that includes an RSVP.
Or a conference website that includes a list of speakers, abstracts, and a schedule.
In all of these cases the data is structured,
and cannot be managed (well) by interfaces essentially treating it as rich text.
Furthermore, while these are often presented statically to end-users, end-users benefit tremendously [7] from
the ability to interactively explore the data via filtering, sorting, aggregates, and other operations.
The end-user need is so strong that there has been research in enabling such capabilities on websites
not designed to provide it [8].
Making it easier for website authors to provide such functionality in the first place
could provide tremendous value to end-users and have a ripple effect on the Web as a whole.
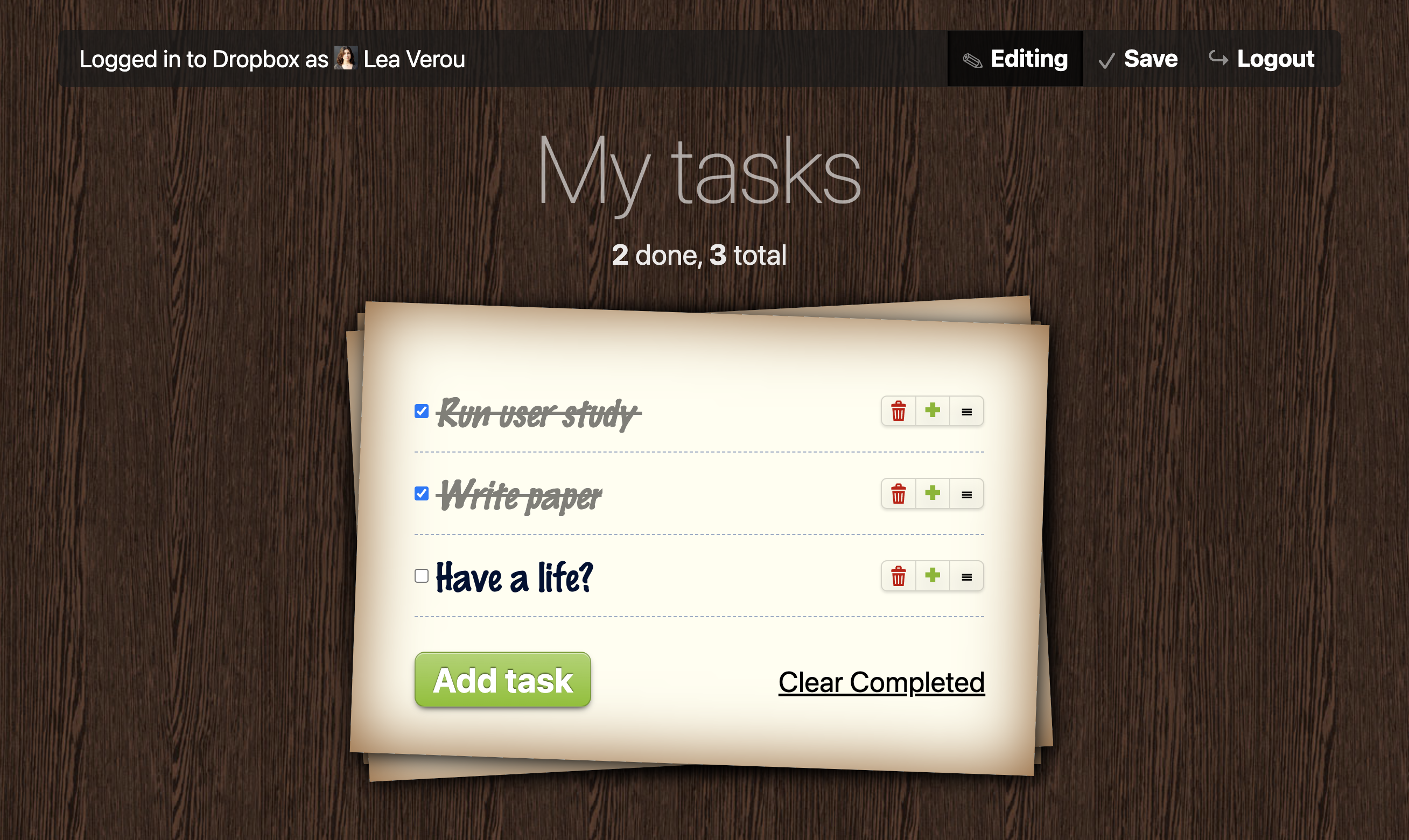
<bodymv-app="todo"mv-storage="https://www.dropbox.com/…/todo.json"><h1>My tasks</h1><p>[count(done)] done, [count(task)] total
<ulmv-listproperty="task"><li><inputtype="checkbox"property="done"/><spanproperty="taskTitle">Do stuff</span></li></ul><buttonmv-action="delete(task where done)">Clear Completed</button></body>
A to-do list application built with Mavo,
showcasing all four core components:
Mavo HTML, Formula², Madata, and Data Update Actions.
It was these recurring pain points around managing, sharing, and transforming data on the Web
that led me to design the Mavo language and associated components.
Mavo is a novel low-code programming language
that extends the declarative syntax of HTML to describe small-scale web applications that manage, store and transform data
(henceforth referred to as data-driven web applications).
Authoring HTML does require some technical skill
(although the ACM cites knowledge of HTML and CSS to be at the K-12 level of computer literacy [9]),
but lowering the barrier of web application programming down to authoring HTML brings it within reach for everyone.
Even for end-users who have never written a line of code,
learning HTML from scratch is a much more manageable task than learning
the entirety of modern web development concepts.
The Mavo language consists of four key components:
Formula², a hierarchical formula language designed from scratch to be easy to use and understand,
even when working with deep hierarchical data structures.
Madata, a set of protocols and APIs
which allow applications to read and store data either locally or to a variety of remote services,
all with the same unified API.
The Mavo HTML syntax, which extends HTML with syntax to describe data-driven web applications
and embeds reactive computation via Formula² expressions and unified storage via Madata URLs.
Data Update Actions, an extension to both Mavo HTML and Formula²,
which allows authoring data manipulation sequences that are triggered by user actions
while largely maintaining the same low threshold (see Section 1.4.1) of Mavo HTML and Formula².
While there is great synergy between these four components,
each of them is an independent contribution of this thesis,
and is useful even without the others.
All four Mavo components share the same design principles,
which are also key features that enabled the growth of the early Web:
No installation, configuration, or maintenance.
Anyone could “join the Web” simply by putting an HTML file on a web server.
Similarly with Mavo, one only needs to put an HTML file on a web server capable of serving static files (no server-side code execution is required) and they can immediately take advantage of Mavo.
This is a direct corollary of Section 1.4.1.
Tinkerability.
A web application’s entire logic is in its HTML file, and can be copied and tweaked.
Furthermore, the data source of any Mavo app can be overridden by simply changing a URL parameter, which enables end-users to repurpose other people’s Mavo apps for their own needs even without copying them to their own file space.
Incremental complexity.
Authors can add additional functionality and complexity in small steps, never needing to swallow a whole new set of ideas in one dose (see Section 1.4.2).
No network effect required.
Unlike social networking sites, Mavo provides immediate benefits to its first adopter, regardless of others’ actions.
It simplifies the author’s management of their data, and offers visitors using existing web browsers a better interface to that data than can be built by typical web authoring tools with the same effort.
Robustness and fault tolerance.
Fault-tolerance is one of the design principles that guided the design of these technologies (see Section 1.4.4).
Reminiscent of the design philosophy of Scratch [10],
Mavo components generally attempt to do something sensible with most input rather than failing with an error message.
A key part of Mavo is its formula language called Formula²
(MavoScript in earlier literature) [11, 12].
Formula² expressions can be embedded almost anywhere in Mavo HTML by delineating them with certain syntactic tokens,
or raw in certain attributes.
Formula² was designed with the explicit goal of reducing the amount of cognitive overhead around abstract data operations,
and allow novices to write formulas that are closer to natural language,
yet still unambiguous and easy to parse.
To achieve this, it introduced several novel concepts, such as:
Implicit reference semantics, where references are resolved based on the context of the formula,
to alleviate users from complex mapping operations or long and fragile reference chains.
Seamless list-valued operations, where operations on lists work just like operations on scalars,
to reduce how much novices need to think about (or even know) the structure of their data.
Robust and forgiving syntax in line with our design principles, which is unusual in the space of formula languages.
The contributions of Formula² are described in more detail in Chapter 4.
While originally developed for Mavo, Formula² has no particular dependence on Mavo concepts,
and can be used to evaluate expressions against any arbitrary hierarchical data structure.
That said, it is primarily useful for systems where the expression and the data have a natural mapping to elements in a visual layout,
whose visual hierarchy largely follows the data hierarchy.
Mavo is one such system, but so are most visual no-code systems.
One of Mavo’s key features is its ability to store data remotely on a variety of cloud services,
without requiring the author to register any OAuth [13] applications or write any authentication code.
Storing and reading data remotely becomes almost as simple as storing it locally,
and one storage service can be seamlessly swapped for another with the same capabilities
without requiring any changes to the application code.
All that users need to do is simply provide a URL that unambiguously identifies the storage location and Mavo takes care of the rest.
Originally hardcoded in Mavo HTML, after launching Mavo as an open source project in 2017,
it quickly became clear that the potential reach of these concepts was broader than Mavo.
Reading and storing data is an integral part of many languages and systems.
Yet, end-users typically have no control or ownership over their data.
This is partly due to business reasons, but also because its is far easier for application developers to store data in a central location they control.
Madata makes it trivial to store data on any supported service, and swap out one service for another.
Storage locations are specified by URLs, most of which can be easily obtained from the user interface of each service.
Then, Madata takes care of the rest (authentication, data transformations, pagination, flags, etc.).
Swapping one service for another is simply a matter of using a different URL, and requires no changes to the application code.
To ensure robustness and prevent centralization, extensibility is essential.
Teaching Madata about new backends requires minimal JavaScript knowledge,
especially for backends that follow certain known protocols (e.g. OAuth 2 [14]).
Madata frees authors from the need to procure servers that can run server-side code, a far more involved task.
Nearly all of Madata runs client-side and interacts with APIs directly from client-side JavaScript.
There is one exception: Authentication.
To facilitate experimenting with different storage locations without having to go through the hassle of registering applications,
Madata introduces the concept of a federated authentication provider.
This is a generalization of Mavo’s original ad hoc authentication server (auth.mavo.io),
which is now simply another Madata authentication provider.
These are servers that encapsulate API keys for supported services, and handle authenticating end-users
and ensuring that users are not misled by malicious applications.
The European Union establishes data portability as a fundamental human right [15].
Madata prototypes a future where end-users can own their data and choose its location
by simply entering a URL in the settings of the application they are using.
If they later change their mind, and wish to store their data elsewhere,
all they need to do is change the URL.
This data portability affords a federated version of data ownership
that places no additional (time or technical skill) burden on end-users than centralized architectures.
A key contribution of this dissertation is Mavo [11], a novel programming language
that extends the declarative syntax of HTML to describe Web applications that manage, store and transform data
(these will henceforth be referred to as data-driven web applications).
Using Mavo, authors with basic HTML knowledge
define complex nested data schemas implicitly as they design their HTML layout.
They need only a few HTML attributes and expressions to transform a static HTML template
into a persistent, data-driven, access-controlled web application
whose data can be edited by direct manipulation of the content in the browser.
Mavo has been evaluated in lab studies, and in the real world, as an open source project.
Unlike current low-code/no-code approaches based on proprietary platforms,
evolving the HTML language provides a solution that is universal and portable,
with no dependence on any particular web infrastructure.
By defining its syntax as an extension of HTML,
all tools that process HTML — some of which do target end-users — can also process Mavo code.
This resulted in the following key ideas and primitives for Mavo HTML:
UI First. User interfaces are less abstract than data, and thus require less technical expertise to reason about.
With Mavo, authors are designing their interface with the tools they are used to;
then they annotate where data goes in it.
The data model is not specified separately, in the abstract; it is generated through these annotations.
We believed that pointing to concrete places on a template is easier for novices than the abstract data modeling tasks that traditional software engineering requires
and our lab studies validated that hypothesis.
Editability. Creating a WYSIWYG interface for editing data in place is as simple as naming the data and choosing an appropriate HTML element for it.
Furthermore, embedding Formula² expressions and Madata URLs in Mavo HTML results in these additional primitives:
Persistence. Data can be stored locally or remotely, on one of the many supported cloud services, by simply providing a storage URL.
Mavo takes care of authentication, if needed.
Access control is enforced by the remote service.
Lightweight computation through a reactive expression language called Formula² similar to spreadsheet formulas but designed for nested schemas like those organically created in most Mavos.
A key feature of Formula² is its novel reference mechanism: properties can be referenced from everywhere in the template, and the relative placement of the expression to the data affects what the named reference resolves to.
Reactive defaults, which are essential to many very common use cases such as smart default values, or editable formulas.
Originally, Formula² was purely reactive and side-effect free.
However, we kept encountering use cases requiring programmatic data modification, triggerred by user actions.
Often applications were almost entirely CRUD with lightweight computation and only one or two simple actions,
but the inability to specify these actions made Mavo unsuitable for these use cases.
After exploring several alternatives, we decided to make these possible by extending Formula² with data update actions [12],
which are only enabled in specific application-dependent contexts (e.g. an mv-action attribute in Mavo).
We then did user research to ensure that our proposed syntax felt natural [16] to novices.
Our design adds minimal complexity but significantly expands the use cases that can be satisfied.
While our research focused on Mavo applications,
the core concepts can be used to extend any reactive formula language with Data update actions
(and since the publication of [12], some commercial no-code systems implemented similar ideas to great success).
In fact, data update actions do not even depend on hierarchical data structures, as this is a common spreadsheet user pain point.
Perhaps this work could serve as a basis to address it.
Mavo is a low-code language, rather than a no-code system2There are currently no no-code languages, though advances in Artificial Intelligence may soon change this.
and targets HTML authors rather than end-users.
While we have made the argument that the effort required for an end-user to become an HTML author is minimal,
and certainly orders of magnitude smaller than the effort required to become a fully-fledged web developer,
any amount of syntax is a barrier to entry for a large group of people.
My later research explored the question If we eliminate HTML syntax, would end-users be able to use and understand Mavo concepts?.
We hypothesized that a domain-specific visual app builder would be more effective.
Since personal tracking use cases are both very common, and a class of applications with minimal network effects,
we decided to start by prototyping Lifesheets, a visual IDE for building custom Quantified Self [17] applications.
In addition to demonstrating that Mavo concepts can largely be understood by end-users with no technical skill beyond spreadsheets,
Lifesheets introduces a novel architecture for empowering users of all technical skills to create web applications that are
portable, malleable, and not dependent on any particular infrastructure.
We conclude the introduction by describing a set of design principles
that guided the development of the languages and systems presented in this thesis.
“Simple things should be easy, complex things should be possible”
— Alan Kay (rumored)
Decades later after Alan Kay, Myers et al formalized this idea
by introducing the concept of threshold and ceiling[18].
The threshold is how difficult it is to learn how to use a system3“or language” is implied., i.e. its learnability;
the ceiling is how much can be done using it, i.e. its expressive power.
Myers said that most successful systems are either
low threshold / low ceiling (easy to learn but limited in expressiveness)
or high threshold / high ceiling (hard to learn, but very powerful).
In other words, most successful systems either trade off learnability for power or the opposite.
It seems clear that balancing a low threshold and a high ceiling would be ideal,
but per Myers et al, it remains a challenge.
While a low threshold and a high ceiling are certainly desirable,
and establish a usability bar that a good majority of systems cannot pass,
they are not sufficient.
Many systems today achieve a low threshold and a high ceiling
by simply combining a low threshold / low ceiling solution
with a high threshold / high ceiling one.
When more power is desired than what the low-threshold solution affords,
users are directed to the high-threshold solution.
This introduces a “usability cliff”,
a point where a small increase in use case complexity results in a disproportionately large increase in UI complexity.
Relevant to this thesis is the example of the HTML5 <video> element.
Its threshold is as low as HTML elements go:
all it takes to embed a video on a webpage with a sleek video player is a single attribute to specify the video source
and another to opt-in to the default playback controls:
<videosrc="myfile.mp4"controls></video>
However, authors cannot customize this playback toolbar beyond hiding buttons.
Once any additional functionality is desired,
such as a subtitle selector, or buttons to jump a few seconds back or forwards,
the only option is to use the JavaScript API that these elements provide and write (a lot of) JavaScript to create a custom video player from scratch.
The threshold and ceiling merely establish the two extremes of a spectrum,
but many use cases are not at either extreme.
For optimal usability, we want a smooth use case complexity to UI complexity curve,
where UI complexity increases gradually with use case complexity.
Incremental user effort should result in incremental value;
there should be no sudden jumps in complexity.
The rate of increase matters too; the flatter, more horizontal the curve, the better.
Essentially, this is a corollary of the Attention Investment Model of Abstraction Use[19],
whose core idea is that programmers have a finite supply of time and attention to invest.
For an investment to be worthwhile, the expected payoff must exceed the cost, unless the risk is too great.
The cost of the investment is the amount of attention by the user that must be devoted to accomplishing a task.
The expected payoff from that investment will be some saving of attentional effort in the future, such as by achieving a good abstract formulation to reduce the amount of effort required to cope with similar problems.
The perceived risk is the extent to which the user believes the investment will not produce the payoff, or that it will lead to even more costs that are not yet apparent.
A cognitive simulation of programmer behavior has validated that
this simple investment model can model many of the actions and decisions made during programming tasks,
both by professional software engineers and end-user programmers [19],
and there is evidence that it is effective in practical language design [19].
A lot of the work presented in this thesis is about either reducing the threshold of web programming,
or making the curve of use case complexity to UI complexity more gradual.
Traditional programming languages often opt for explicit paradigms,
where every parameter of the computation is specified by the programmer.
Everything is clear cut, and there is no ambiguity,
but to avoid potentially incorrect inference, this design offloads a lot of work to the programmer, increasing cognitive load.
This rigidity can be frustrating for novices,
who are more familiar with the communication paradigms of natural language,
which favor implicitness and ambiguity [20, 21].
In natural language, the receiver of a message will largely infer several concepts from context,
and ask for clarification when needed.
A compiler cannot ask for clarification, it can only produce errors.
The “clarification” is essentially the programmer fixing the issue.
Heuristic algorithms that attempt to infer author intent from incomplete input
can often improve user experience by reducing the amount of explicit input required
and the amount of errors produced (which we know are discouraging).
However, when the inference is incorrect,
it is essential to provide a way for users to override the inferred behavior
and provide explicit input.
CSS selectors [22] are a querying language for DOM trees,
HTML’s hierarchical object model.
When declarations from two CSS rules conflict,
the browser must decide which one to apply.
Rather than a simple rule like “last one wins”,
CSS uses an elaborate algorithm taking many factors into account (The Cascade).
One of these factors is the specificity of the selector,
which assigns a weight to each selector based on its structure.
Essentially this is an inference mechanism that attempts to guess importance by proxy of querying logic.
For example, using an id selector (#foo) which in theory targets only a single element
is more specific than using a class selector (.foo) which targets several elements,
which in turn is more specific than using a tag selector (div) which targets any element of that type.
This works somewhat well in practice, but there are many cases where the inference is incorrect.
As a particularly egregious example, :not(#foo) targets all elements except one,
yet enjoys the same high specificity as #foo.
For years, this was a source of frustration for CSS authors,
since CSS did not provide a general mechanism
for lowering the specificity of a selector, only workarounds to increase it.
This changed with the introduction of the :where() pseudo-class
(proposed by the author in 20174github.com/w3c/csswg-drafts/issues/1170), and with Cascade Layers.
The importance of providing overrides depends on the frequency and consequences of incorrect inferences.
In some cases, the presence of alternative ways to solve the same problem can be a sufficient escape hatch.
In JS, array.concat(value) attempts to infer intent based on the type of the argument(s) passed.
If the argument is an array, it will append the array values to the original array,
rather than appending the array itself.
If the argument is not an array, it will append the argument itself, even when it’s a different iterable, e.g. a Set.
In this case, when a different behavior is desired the escape hatch is to use different language features, such as the spread operator, or array.push(),
not to add options to array.concat().
In some ways, this is a corollary of Section 1.4.2:
inference is making simple things easy, while escape hatches are making complex things possible.
HTML is possibly the most tolerant mainstream computer language.
This is no accident; tolerance was one of its earliest design principles [23–25].
Eliminating error messages does not eliminate errors.
However, when a program does something, even if it is not correct,
it feels closer to working and is less discouraging than a program that does not run (or compile) at all [10].
Per [26], there are no errors; all operations are iterations towards a goal.
Typing mistakes or illegal statements can be thought of as an approximation.
The language’s job is then to aid the user in rapid convergence to the desired goal.
In some cases, that may be achieved via inference (see Section 1.4.3),
in others by failing gracefully.
Notifying the user that there is a problem is important, but rarely requires complete and total failure.
This kind of resilience is especially important on the Web platform,
where the environment is unpredictable and the user base is vast and diverse.
There is no guarantee that when the error condition occurs, the user will be the website author.
Thus, resilience ensures a better user experience for all Web users.
Chapter 2 positions this thesis in the broader context of related research and tools that aim to make web application development easier.
From there, Chapter 3 to Chapter 6, and then Chapter 9 describe various languages and systems
democratizing web application development and empowering data ownership from different angles:
Chapter 3 introduces the Mavo HTML language and briefly describes Formula2 and Madata and how Mavo HTML integrates them.
Chapter 4 expands on the Formula² hierarchical formula language.
Chapter 5 expands on the Madata JavaScript API and federated authentication architecture.
Chapter 6 introduces Data Update Actions, a way to add programmatic data manipulation to reactive formula languages.
Chapter 9 introduces Lifesheets, a domain-specific visual application builder for building Mavo applications for personal tracking.
These chapters present the latest design of each technology, which is often the result of multiple iterations
following insights from user studies and deployments.
They include results from formative needfinding studies,
example use cases,
descriptions of system specifications, and implementation details.
Then, Chapter 7 provides an overview of the various studies conducted to evaluate these systems,
and provides context for the status of Mavo technologies at the time each study was conducted.
These include results from lab evaluations, case studies, and wide deployments as open source projects.
We decided to present them after the description of all four languages and systems,
as many studies were evaluating more than one component.
Chapter 8 presents a series of case studies of Mavo applications showcasing
all technologies in the Mavo ecosystem working together to produce high fidelity applications.
Some were created by Mavo users, and some by the author.
Some are included because they showcase interesting patterns for common use cases,
and others because they push the boundaries of what is possible with Mavo.
Each case study is accompanied by a description of key points from its architecture and implementation,
as well as a list of limitations it exposes in the current Mavo ecosystem.
Last, Chapter 10 summarizes design lessons from these languages and systems, their user studies and their deployments,
discusses current limitations, and proposes future research directions.
The thesis concludes in Chapter 11 by reviewing and summarizing the contributions of this work.
Berners‐Lee, T., Cailliau, R., Groff, J. and Pollermann, B. 1992. World‐Wide Web: The Information Universe. Internet Research. 2, (Jan. 1992), 52–58. 10.1108/eb047254.
Cited in1, and
2
Koch, R. 2011. The 80/20 principle: The secret of achieving more with less: Updated 20th anniversary edition of the productivity and business classic. Hachette UK.
Cited in1
Chambers, C. and Scaffidi, C. 2010. Struggling to Excel: A Field Study of Challenges Faced by Spreadsheet Users. 2010 IEEE Symposium on Visual Languages and Human-Centric Computing (Sep. 2010), 187–194. 10.1109/VLHCC.2010.33.
Cited in1
Huynh, D.F., Karger, D.R. and Miller, R.C. 2007. Exhibit: Lightweight Structured Data Publishing. Proceedings of the 16th International Conference on World Wide Web - WWW ’07. (2007), 737. 10.1145/1242572.1242672.
Cited in1
Seehorn, D., Carey, S., Fuschetto, B., Lee, I., Moix, D., O’Grady-Cunniff, D., Owens, B.B., Stephenson, C. and Verno, A. 2011. CSTA K--12 computer science standards: revised 2011. (2011).
Cited in1
Maloney, J., Resnick, M., Rusk, N., Silverman, B. and Eastmond, E. 2010. The Scratch Programming Language and Environment. ACM Trans. Comput. Educ. 10, (Nov. 2010), 16:1-16:15. 10.1145/1868358.1868363.
Cited in1, and
2
Verou, L., Zhang, A.X. and Karger, D.R. 2016. Mavo: Creating interactive data-driven web applications by authoring HTML. UIST 2016 - Proceedings of the 29th Annual Symposium on User Interface Software and Technology (2016), 483–496. 10.1145/2984511.2984551.
Cited in1, and
2
Verou, L., Alrashed, T. and Karger, D. 2018. Extending a reactive expression language with data update actions for end-user application authoring. UIST 2018 - Proceedings of the 31st Annual ACM Symposium on User Interface Software and Technology (2018), 379–387. 10.1145/3242587.3242663.
Cited in1,
2, and
3
Kuebler-Wachendorff, S., Luzsa, R., Kranz, J., Mager, S., Syrmoudis, E., Mayr, S. and Grossklags, J. 2021. The Right to Data Portability: conception, status quo, and future directions. Informatik Spektrum. 44, (Aug. 2021), 264–272. 10.1007/s00287-021-01372-w.
Cited in1
Myers, B., Hudson, S.E. and Pausch, R. 2000. Past, Present, and Future of User Interface Software Tools. ACM Transactions on Computer-Human Interaction. 7, (2000), 3–28. 10.1145/344949.344959.
Cited in1
Blackwell, A. and Burnett, M. 2002. Applying attention investment to end-user programming. Proceedings IEEE 2002 Symposia on Human Centric Computing Languages and Environments (Sep. 2002), 28–30. 10.1109/HCC.2002.1046337.
Cited in1,
2, and
3
Bonar, J. and Soloway, E. 1983. Uncovering principles of novice programming. Proceedings of the 10th ACM SIGACT-SIGPLAN symposium on Principles of programming languages (New York, NY, USA, Jan. 1983), 10–13. 10.1145/567067.567069.
Cited in1
Ma, L. 2007. Investigating and Improving Novice Programmers’ Mental Models of Programming Concepts (Doctoral dissertation, University of Strathclyde).
Cited in1
Norman, D.A. 1983. Design principles for human-computer interfaces. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (New York, NY, USA, Dec. 1983), 1–10. 10.1145/800045.801571.
Cited in1